概述
Elasticsearch是一个基于Apache Lucene的开源搜索引擎,其依靠Lucene完成索引创建和搜索功能,可以将ElstaicSearch理解为是一个Lucene的分布式封装的搜索引擎。
前置知识
倒排索引
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现,例如需要在手机数据中查询名称包含苹果的手机,需要通过如下 sql 实现:
1 | select * from phone_table where phone_brand like '%苹果手机%'; |
这种实现方式实际会存在很多问题,例如需要全表扫描,性能差,无法得内容与搜索条件的相关性等,为了高效的实现全文检索,我们可以通过倒排索引来解决
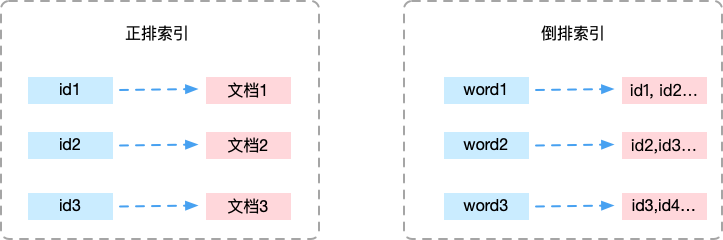
倒排索引是区别于正排索引的概念
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
FST算法
FST全程Finite State Transducer 全称有穷状态转换器;FST是一种类似于字典的数据结构,但是它是k:v结构的,使用FST有两个优先
- 空间占用小:通过对字典中单词前缀和后缀的重复利用,压缩了存储空间
- 查询效率快:查询速度不会超过
O(len(str))
如果我们要对 cat、 deep、 do、 dog、dogs这五个单词进行插入构建FST(工具演示:http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it%21),执行过程如下:
插入cat, 每个字母一条边,其中t边指向终点

插入deep, 与前一个单词 cat 进行最大前缀匹配,发现没有匹配则直接插入,P边指向终点

插入do, 与前一个单词deep进行最大前缀匹配,发现是 d,则在d边后增加新边o,o边指向终点

插入dog, 与前一个单词 do 进行最大前缀匹配,发现是 do,则在o边后增加新边g,g边指向终点

插入dogs, 与前一个单词 dog 进行最大前缀匹配,发现是dog,则在g后增加新边s,s边指向终点。

Lucene写入原理
基本概念
在Lucene中,写入数据的基本单元称之为Document,一个Document是由Field构成,Field是Term的集合,Segment是最小的独立索引单元,由多个Documents构成;在每个Segment范畴内,每个Document都被分配到了一个唯一的数字ID, 称之为DocID, 同时根据每个Field的名字定一个唯一的FieldNaming,对于索引字段进到Postings之前也会被分配一个唯一的TermID。Field除了FieldNaming之外也有一个FieldNumber,与DocID和TermID一样都是一个自增的数值。
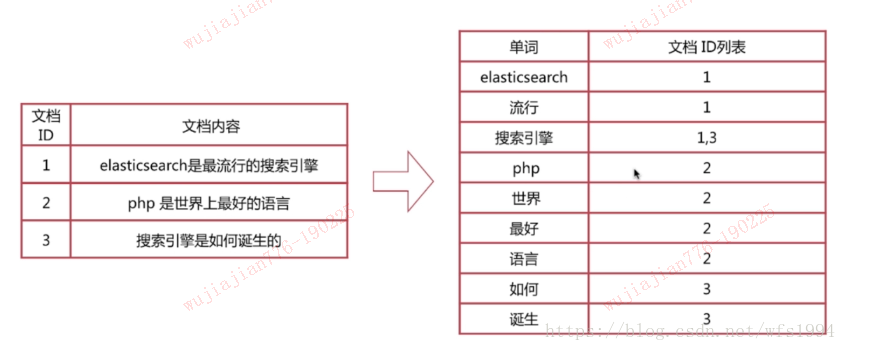
倒排索引需要将 terms 映射到包含该单词 (term) 的文档列表,这样的映射列表我们称之为:倒排列表(postings list)。具体某一条映射数据称之为:倒排索引项(Posting)。
Lucene中倒排索引的结构
根据倒排索引的概念,最简单的我们可以用一个Map来描述这个结构, Map 的 Key 存储分词后的单词(也叫Term),Map的Value存储一些列的文档ID的集合,但是全文搜索引擎在海量数据的情况下需要存储大量的文本,如果是用Map存储Directory的话有这样几个明显的缺点:
- Dictionary 是非常大的(比如我们搜索中的一个字段在Directory里可能有上千万个Term)因此存储所有的Term需要大量的内存
- Postings 也可能会占据大量的存储空间(一个Term多的有几百万个doc)
- Posting List 不仅仅需要包含文档的id,为了加快搜索的速度还需要包含更多信息,比如下面这些
- 文档 id(DocId, Document Id),包含单词的所有文档唯一id,用于去正排索引中查询原始数据
- 词频(TF,Term Frequency),记录 Term 在每篇文档中出现的次数,用于后续相关性算分
- 位置(Position),记录 Term 在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)
- 偏移(Offset),记录 Term 在每篇文档的开始和结束位置,用于高亮显示等
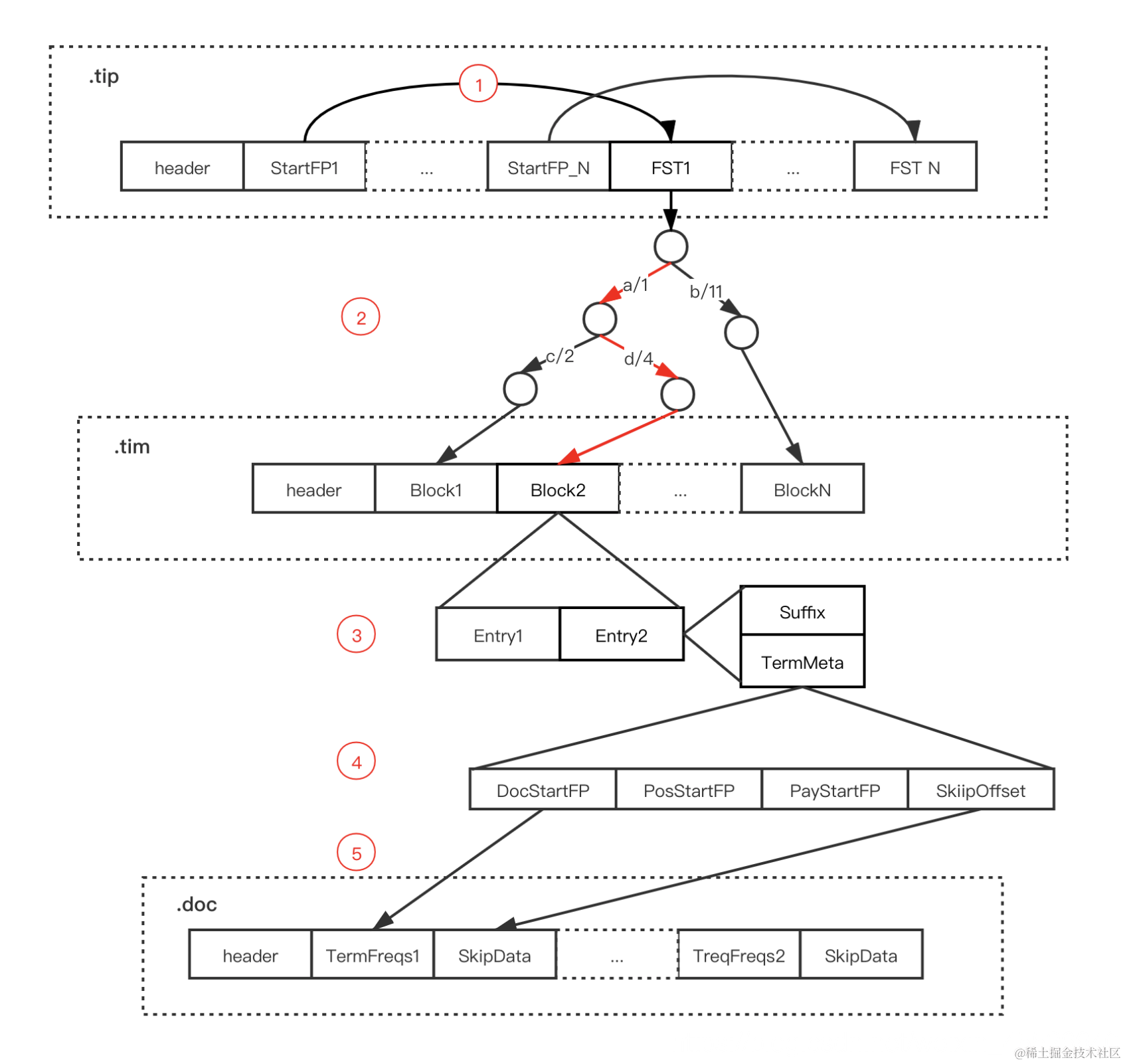
因此上面说的基于 Map 的实现方式几乎是不可行的。在海量数据背景下,倒排索引的实现直接关系到存储成本以及搜索性能,为此,Lucene 引入了多种巧妙的数据结构和算法,同时也把倒排索引的结构组织成如下图所示:

- Lucene把用于存储Term的索引文件叫Terms Index,它的后缀是
.tip - 把Postings信息分别存储在
.doc、.pay、.pox,分别记录Postings的DocId信息和Term的词频、Payload信息、pox是记录位置信息 - Terms Dictionary的文件后缀称为
.tim,它是Term与Postings的关系纽带,存储了Term和其对应的Postings文件指针。
通过Terms Index(.tip) 能够快速地在Terms Dictionary(.tim) 中找到你的想要的Term,以及它对应的Postings文件指针与Term在Segment作用域上的统计信息。
postings: 实际上Postings包含的东西并不仅仅是DocIDs(我们通常把这一个有序文档编号系列叫DocIDs),它还包括文档编号、以及词频、Term在文档中的位置信息、还有Payload数据。

什么是Term Index
Terms Index存储在.tip文件中,实际张是有一个或者多个FST组成的,Segment上每个字段都有自己的一个FST(FST Index)记录在.tip上,所以图中FST Index的个数即是Segment拥有字段的个数。

什么是Term Directory
Term Directory存储了Index field 经过去重、时态统一、大小写统一、近义词处理等操作后的词项数据,最后存储在.tim文件中(也就是Term Directory 存储所有的Term数据),同时它也是 Term 与 Postings 的关系纽带,存储了每个 Term 和其对应的 Postings 文件位置指针。通过Term Directory可以知道Term的统计信息,包括Term在Segment中出现的频率等。
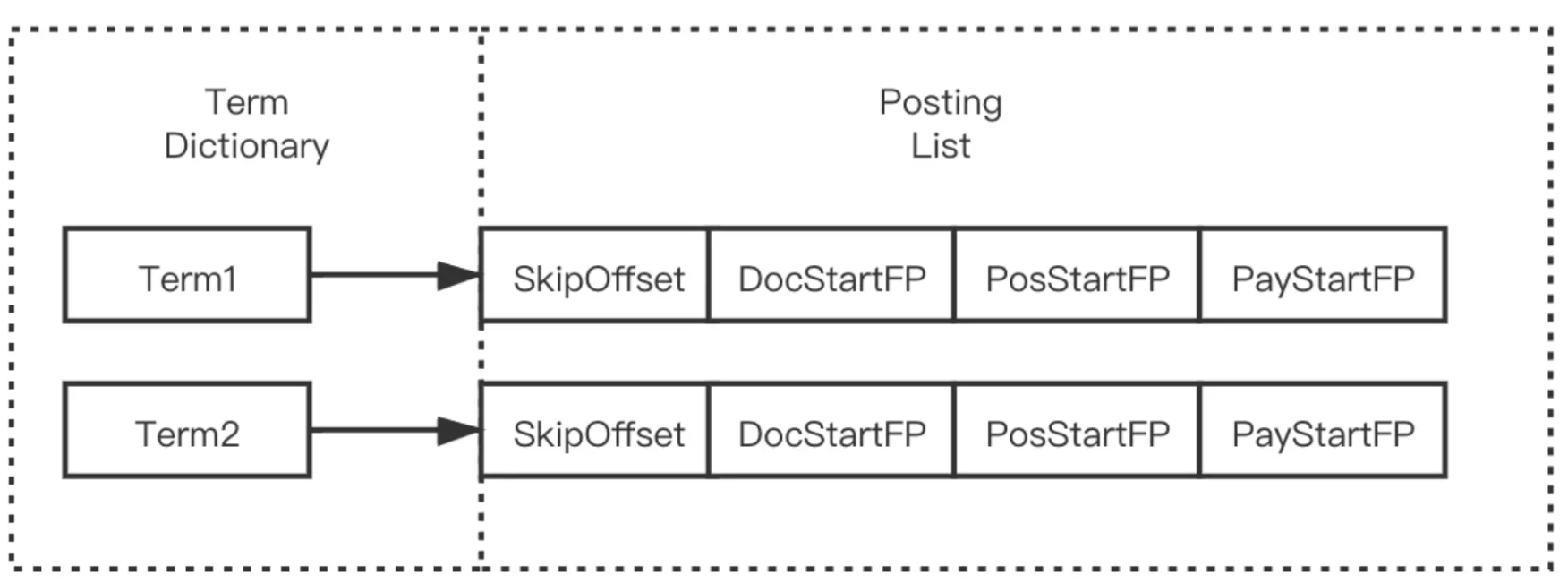
Terms Dictionary 内部采用 NodeBlock 这种结构对 Term 进行压缩存储,处理过程会将相同前缀的 Term 压缩为一个 NodeBlock,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block,如下图所示:
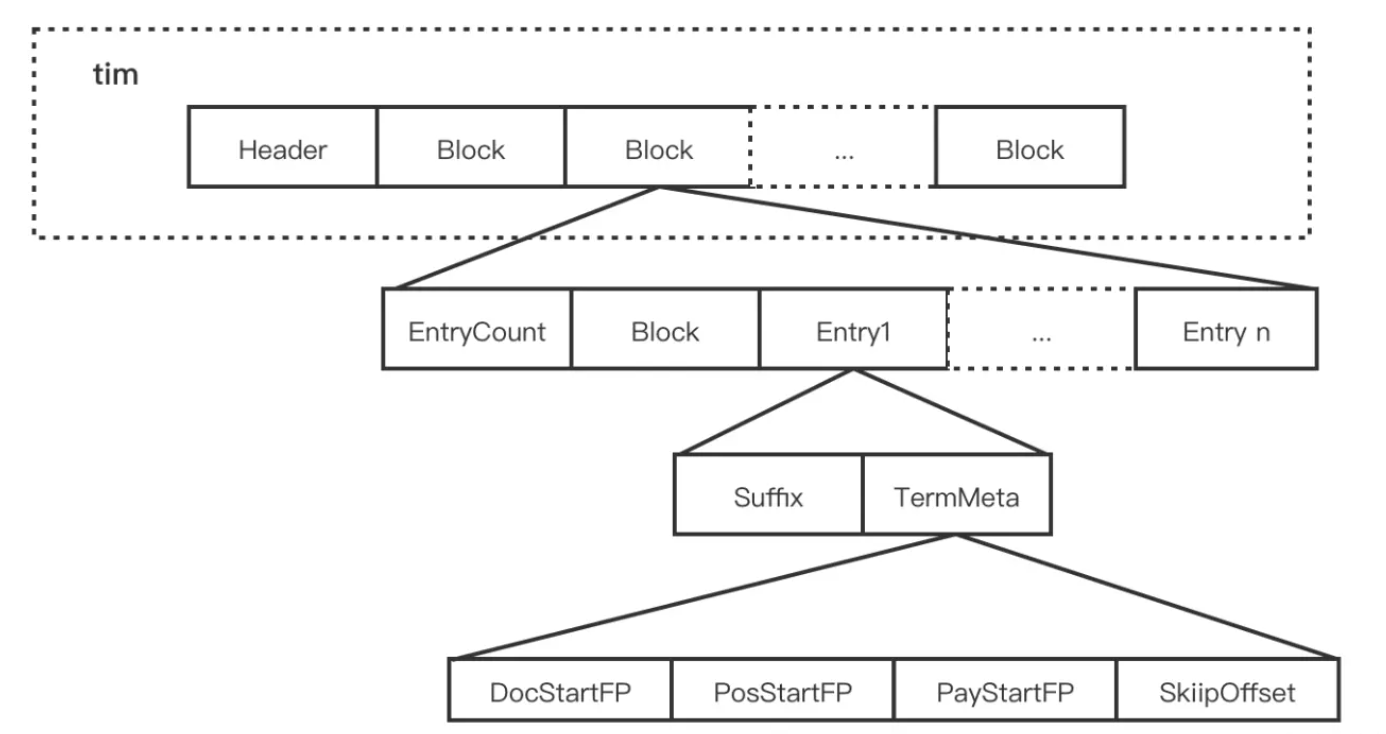
什么是PostingList
PostingList 包含文档 id、词频、位置等多个信息,这些数据之间本身是相对独立的,因此 Lucene 将 Postings List 拆成三个文件存储:
- .doc文件:记录 Postings 的 docId 信息和 Term 的词频
- .pay文件:记录 Payload 信息和偏移量信息
- .pos文件:记录位置信息
这个做法有没有点列式存储的味道?其好处也很明显:一来可以提高读取效率,因为基本所有的查询都会用 .doc 文件获取文档 id,但一般的查询仅需要用到 .doc 文件就足够了,只有对于近似查询等位置相关的查询才需要用位置相关数据, 二来这样存储数据很方便对数据进行压缩
三个文件整体实现差不太多,这里仅介绍.doc 文件,.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构,其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表结构,用于实现 TermFreqs 内部的快速跳转
Posting List 采用多个文件进行存储,最终我们可以得到每个 Term 的如下信息:
- SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置。
- DocStartFP:是当前 term 信息在 .doc 文件中的文档 ID 与词频信息的起始位置。
- PosStartFP:是当前 term 信息在 .pos 文件中的起始位置。
- PayStartFP:是当前 term 信息在 .pay 文件中的起始位置。
为了压缩Posting List的存储空间,需要对Posting List进行压缩,Lucene采用的压缩算法是: FOR + RBM
Lucene的搜索过程
lucene的搜索过程如下:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData快速跳转
参考文档
- 捋一捋ElasticSearch(三)| Lucene存储引擎 — 推荐阅读
- ES的FST原理 — 推荐阅读
- ElasticSearch倒排索引使用算法FST — 可以看看~
- lucene字典实现原理——FST – 也可以看看~
- ElasticSearch索引核心原理
- Lucene 3.0 原理与代码分析完整版