概述
什么是goroutine? Goroutine 可以看作对 thread 加的一层抽象,它更轻量级,可以单独执行。
goroutine(协程) 跟 线程的区别
goroutine跟线程的区别可以从内存消耗、创建与销毀、切换三个维度说明
- 内存创建: 创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
- 创建和销毀: 线程创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
- 切换: 当 threads 切换时,需要保存各种寄存器,以便将来恢复, 而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。因此goroutines 切换成本比 threads 要小得多。
G-P-M模型概述
在 Go 语言中,每一个 goroutine 是一个独立的执行单元,相较于每个 OS 线程固定分配 2M 内存的模式,goroutine 的栈采取了动态扩容方式, 初始时仅为2KB,随着任务执行按需增长,最大可达 1GB(64 位机器最大是 1G,32 位机器最大是 256M),且完全由 golang 自己的调度器 Go Scheduler 来调度。此外,GC 还会周期性地将不再使用的内存回收,收缩栈空间。 因此,Go 程序可以同时并发成千上万个 goroutine 是得益于它强劲的调度器和高效的内存模型。

将 goroutines 调度到线程上执行,仅仅是 runtime 层面的一个概念,在操作系统之上的层面,在golang中有三个基础的结构体来实现 goroutines 的调度。g,m,p, 俗称GPM模型:
- G: 表示 Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
- P: Processor,表示逻辑处理器, 对 G 来说,P 相当于 CPU 核,G 只有绑定到 P(在 P 的 local runq 中)才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量),P 的数量由用户设置的 GOMAXPROCS 决定,但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。
- M: Machine,OS 线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础,M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
- 每个 P 维护一个 G 的本地队列;
- 当一个 G 被创建出来,或者变为可执行状态时,就把他放到 P 的本地可执行队列中,如果满了则放入Global;
- 当一个 G 在 M 里执行结束后,P 会从队列中把该 G 取出;如果此时 P 的队列为空,即没有其他 G 可以执行, M 就随机选择另外一个 P,从其可执行的 G 队列中取走一半。
除了GPM外,还有两个比较重要的组件: 全局可运行队列(GRQ)和本地可运行队列(LRQ)。 LRQ 存储本地(也就是具体的 P)的可运行 goroutine,GRQ 存储全局的可运行 goroutine,这些 goroutine 还没有分配到具体的 P。
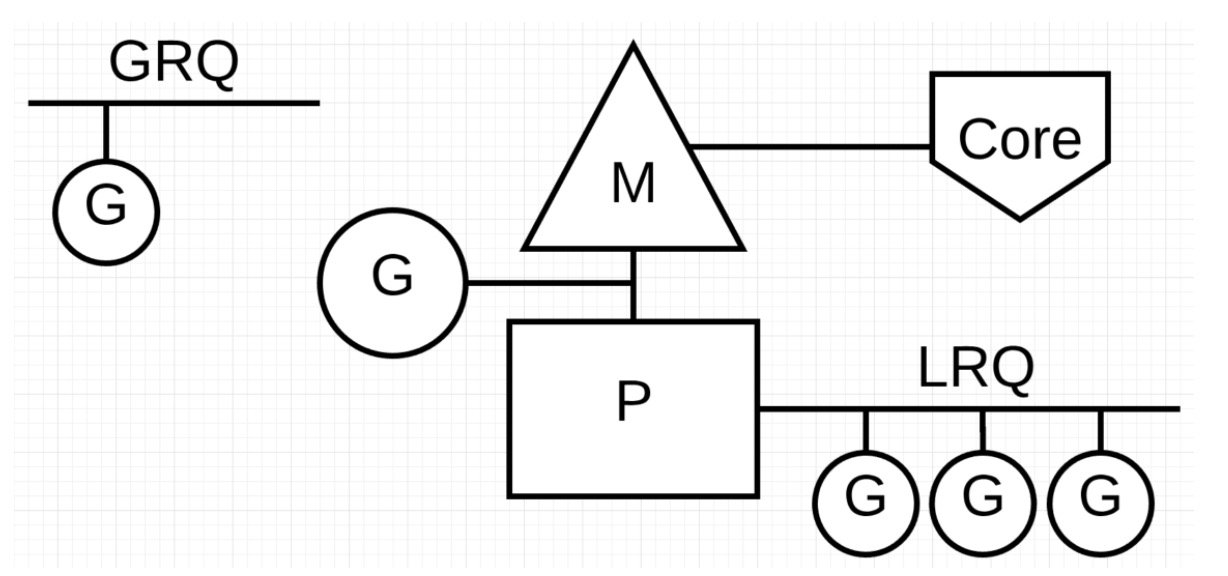
调度过程
- 当通过 go 关键字创建一个新的 goroutine 的时候,它会优先被放入 P 的本地队列。
- 为了运行 goroutine,M 需要持有(绑定)一个 P,接着 M 会启动一个 OS 线程,循环从 P 的本地队列里取出一个 goroutine 并执行。
- 执行调度算法:当 M 执行完了当前 P 的 Local 队列里的所有 G 后,P 也不会就这么在那划水啥都不干,它会先尝试从 Global 队列寻找 G 来执行,如果 Global 队列为空,它会随机挑选另外一个 P,从它的队列里中拿走一半的 G 到自己的队列中执行。
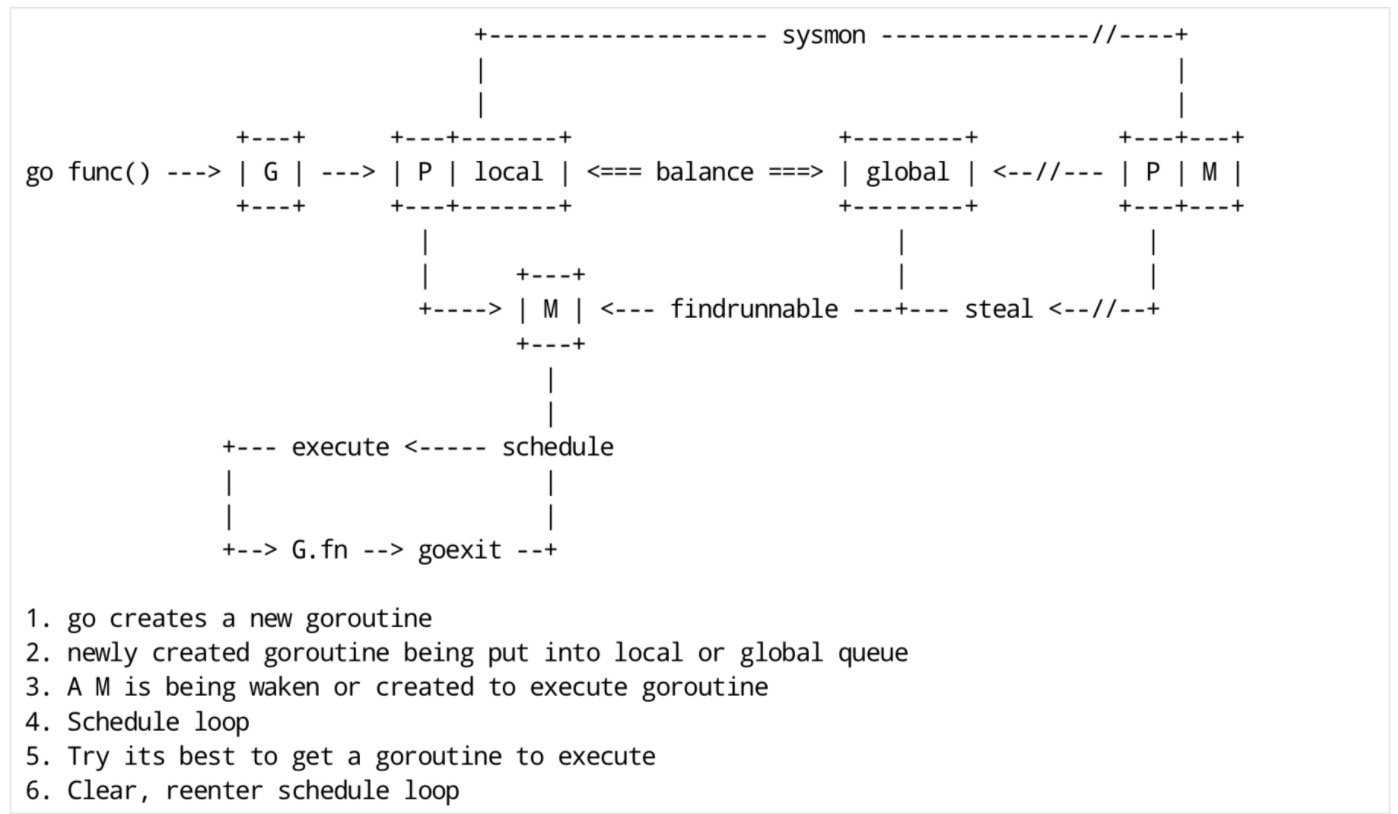
调度时机
在四种情形下,goroutine 可能会发生调度,但也并不一定会发生,只是说 Go scheduler 有机会进行调度。
- 使用关键字
go: go 创建一个新的 goroutine,Go scheduler 会考虑调度 - GC: 由于进行 GC 的 goroutine 也需要在 M 上运行,因此肯定会发生调度。当然,Go scheduler 还会做很多其他的调度,例如调度不涉及堆访问的 goroutine 来运行。GC 不管栈上的内存,只会回收堆上的内存
- 系统调用: 当 goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度上来
- 内存同步访问: atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走。等条件满足后(例如其他 goroutine 解锁了)还会被调度上来继续运行
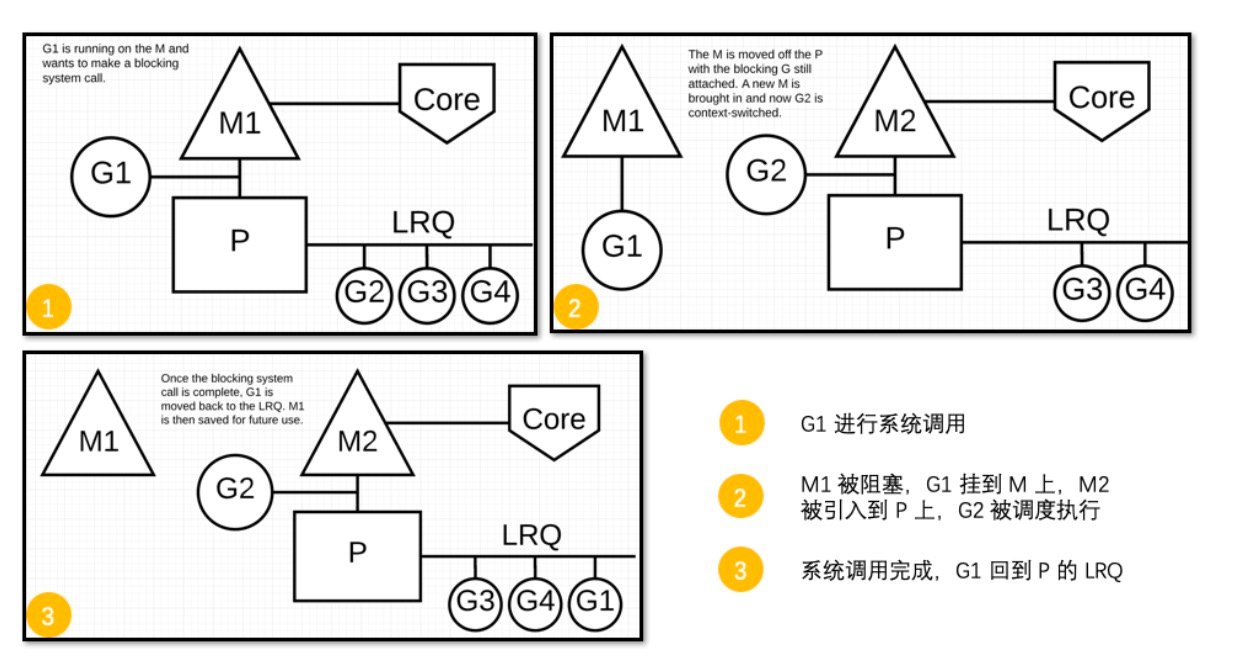
同步/异步系统调用
当 G 需要进行系统调用时,根据调用的类型,它所依附的 M 有两种情况:同步和异步。
对于同步的情况,M 会被阻塞,进而从 P 上调度下来,P 可不养闲人,G 仍然依附于 M。之后,一个新的 M 会被调用到 P 上,接着执行 P 的 LRQ 里嗷嗷待哺的 G 们。一旦系统调用完成,G 还会加入到 P 的 LRQ 里,M 则会被“雪藏”,待到需要时再“放”出来。
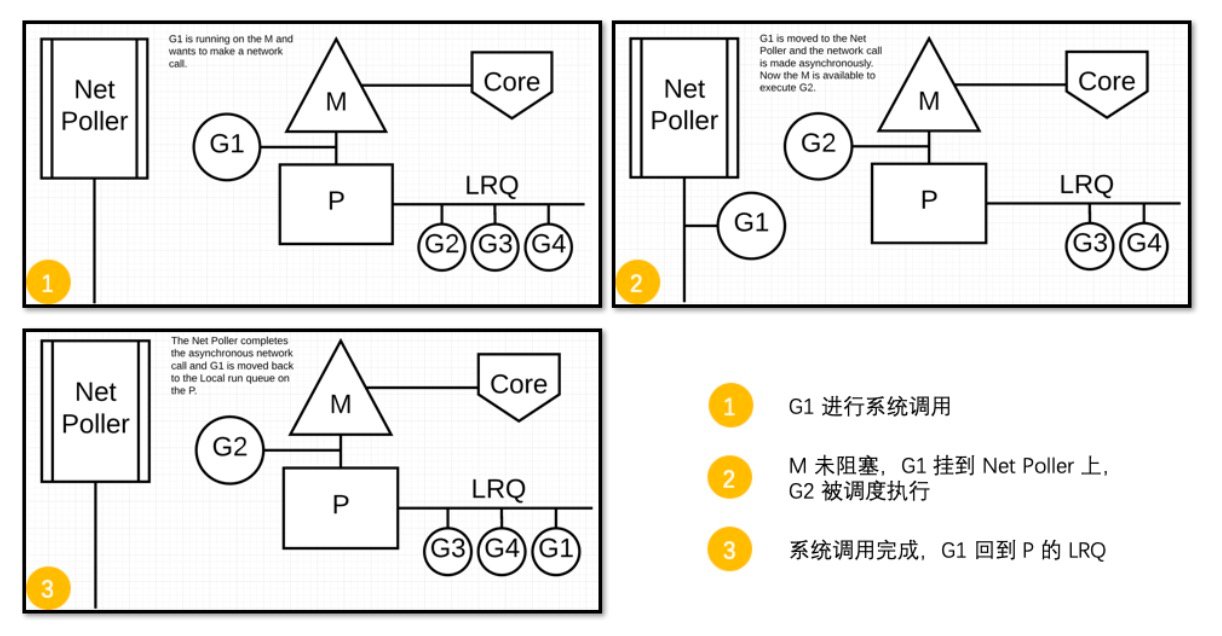
对于异步的情况,M 不会被阻塞,G 的异步请求会被“代理人” network poller 接手,G 也会被绑定到 network poller,等到系统调用结束,G 才会重新回到 P 上。M 由于没被阻塞,它因此可以继续执行 LRQ 里的其他 G。
goroutine状态流转
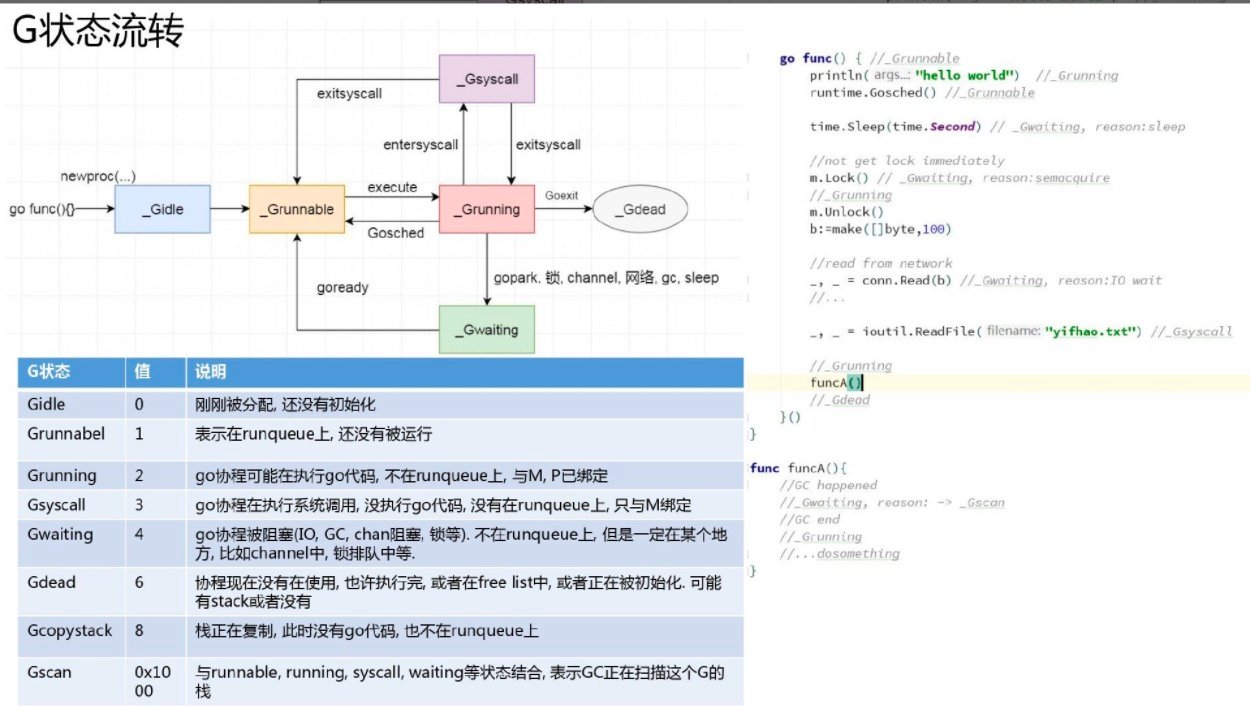
GPM结构
G 结构
g是goroutine的缩写,是goroutine的控制结构,是对goroutine的抽象。看下它内部主要的一些结构:
1 | type g struct { |
其中包含了栈信息stackbase和stackguard,有运行的函数信息fnstart。这些就足够成为一个可执行的单元了,只要得到CPU就可以运行。goroutine切换时,上下文信息保存在结构体的sched域中。goroutine切换时,上下文信息保存在结构体的sched域中。goroutine是轻量级的线程或者称为协程,切换时并不必陷入到操作系统内核中,很轻量级。
1 | struct Gobuf |
P 结构
P是Processor的缩写。结构体P的加入是为了提高Go程序的并发度,实现更好的调度。M代表OS线程。P代表Go代码执行时需要的资源。
1 | type p struct { |
跟G不同的是,P不存在waiting状态。MCache被移到了P中,但是在结构体M中也还保留着。在P中有一个Grunnable的goroutine队列,这是一个P的局部队列。当P执行Go代码时,它会优先从自己的这个局部队列中取,这时可以不用加锁,提高了并发度。如果发现这个队列空了,则去其它P的队列中拿一半过来,这样实现工作流窃取的调度。这种情况下是需要给调用器加锁的。
M 结构
1 | type m struct { |
和G类似,M中也有alllink域将所有的M放在allm链表中。lockedg是某些情况下,G锁定在这个M中运行而不会切换到其它M中去。M中还有一个MCache,是当前M的内存的缓存。M也和G一样有一个常驻寄存器变量,代表当前的M。同时存在多个M,表示同时存在多个物理线程。
参考文档
- 深度解密go语言之scheduler //绕全成大佬的解密完全看不懂
- GoLang GPM模型 //写的不错
- 万字长文深入浅出 Golang Runtime //之前go夜读有看到分享,说的贼好
- go中的协程-goroutine的底层实现 // pdd 牛皮