Cgroup简述
在Docker中,容器使用Linux namespace技术进行资源隔离,使得容器中的进程看不到别的容器的资源,但是容器内的进程仍然可以任意地使用主机的 CPU 内存等资源,如果某一个容器使用的主机资源过多,可能导致主机的资源竞争,进而影响业务。那如果我们想限制一个容器资源的使用(如 CPU、内存等)应该如何做呢?
这里就需要用到 Linux 内核的另一个核心技术cgroups。那么究竟什么是cgroups?cgroups(全称:Control Groups)是 Linux 内核的一个功能,它可以实现限制进程或者进程组的资源(如 CPU、内存、磁盘 IO 等)。
在 2006 年,Google 的工程师( Rohit Seth 和 Paul Menage 为主要发起人) 发起了这个项目,起初项目名称并不是cgroups,而被称为进程容器(process containers)。在 2007 年cgroups代码计划合入Linux 内核,但是当时在 Linux 内核中,容器(container)这个词被广泛使用,并且拥有不同的含义。为了避免命名混乱和歧义,进程容器被重名为cgroups,并在 2008 年成功合入 Linux 2.6.24 版本中。cgroups目前已经成为 systemd、Docker、Linux Containers(LXC) 等技术的基础。
Cgroup 功能组件
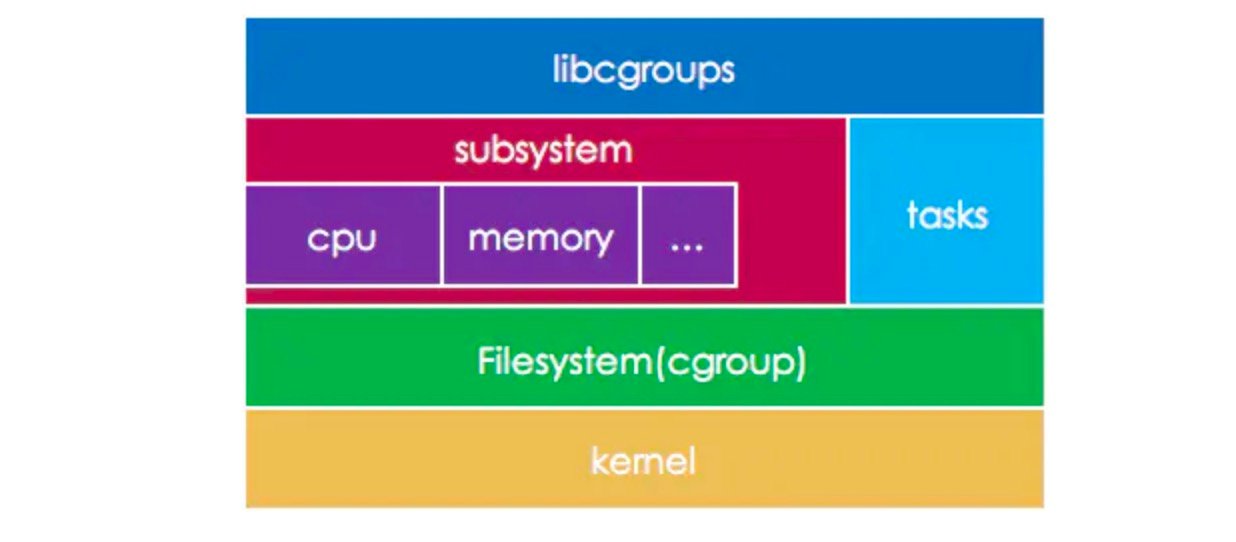
cgroups功能的实现依赖于三个核心概念:子系统、控制组、层级树。
- 控制组(cgroup): 控制组是对进程分组管理的一种机制,一个Cgroup包含一组进程,并可以在上面添加添加Linux Subsystem的各种参数配置,将一组进程和一组Subsystem的系统参数关联起来。
- 子系统(subsystem):是一个内核的组件,一个子系统代表一类资源调度控制器。例如内存子系统可以限制内存的使用量,CPU 子系统可以限制 CPU 的使用时间。不同版本的Kernel支持的子系统有所偏差,可以通过
cat /proc/cgroups查看。 - 层级树(hierarchy):是由一系列的控制组(Cgroup) 按照树状结构排列组成的。这种排列方式可以使得控制组(Cgroup) 拥有父子关系,子控制组默认拥有父控制组的属性,也就是子控制组会继承于父控制组。比如,系统中定义了一个控制组 c1,限制了 CPU 可以使用 1 核,然后另外一个控制组 c2 想实现既限制 CPU 使用 1 核,同时限制内存使用 2G,那么 c2 就可以直接继承 c1,无须重复定义 CPU 限制。每个 hierarchy
在初始化时会有默认的CGroup(Root CGroup)。 - 任务(task): 进程(
process)在cgroups中称为task,taskid就是pid。 - libcgroups:一个开源软件,提供了一组支持cgroups的应用程序和库,方便用户配置和使用cgroups。目前许多发行版都附带这个软件。
linux 支持的子系统
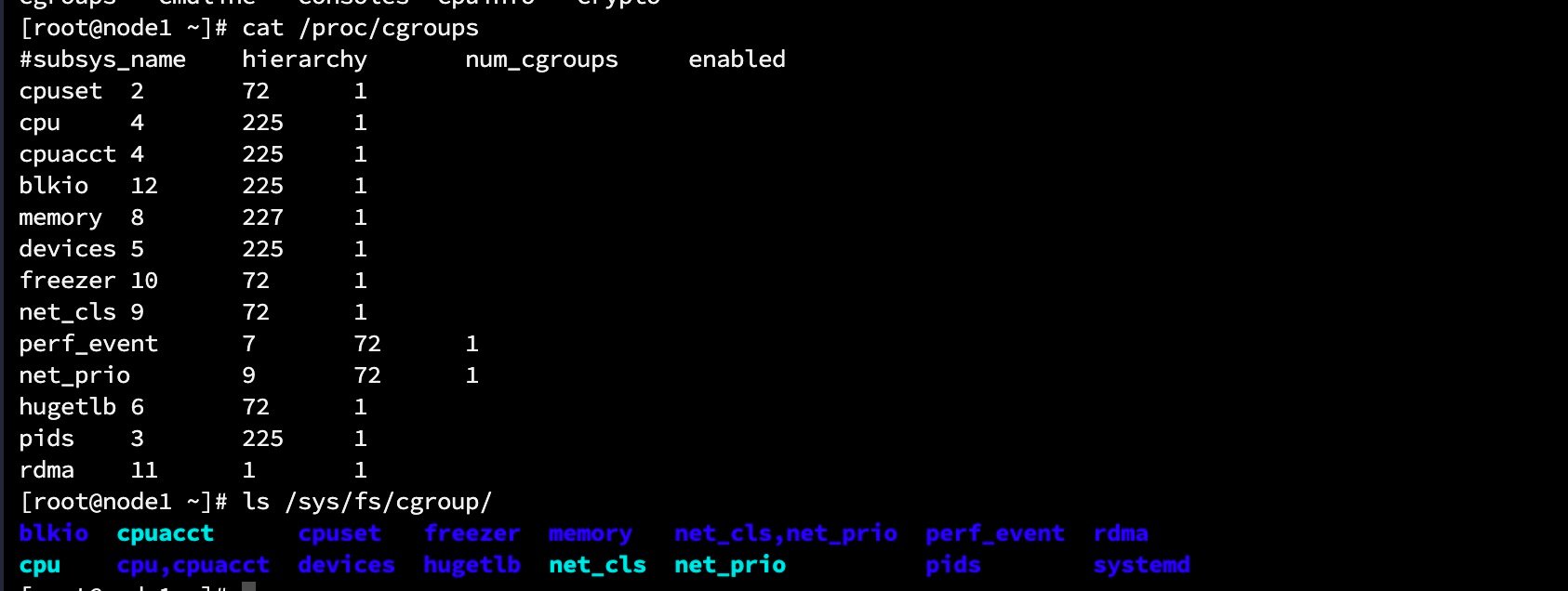
不同版本的Kernel支持的子系统有所偏差,可以通过cat /proc/cgroups查看。
blkio对块设备(比如硬盘)的IO进行访问限制cpu设置进程的CPU调度的策略, 比如CPU时间片的分配cpuacct统计/生成cgroup中的任务占用CPU资源报告cpuset在多核机器上分配给任务(task)独立的CPU和内存节点(内存仅使用于NUMA架构)devices控制cgroup中对设备的访问freezer挂起(suspend) / 恢复 (resume)cgroup中的进程memory用于控制cgroup中进程的占用以及生成内存占用报告net_cls使用等级识别符(classid)标记网络数据包,这让 Linux 流量控制器 tc (traffic controller) 可以识别来自特定 cgroup 的包并做限流或监控net_prio设置cgroup中进程产生的网络流量的优先级hugetlb限制使用的内存页数量pids限制任务的数量ns可以使不同cgroups下面的进程使用不同的namespace. 每个subsystem会关联到定义的cgroup上,并对这个cgoup中的进程做相应的限制和控制.
挂载cgroup 文件系统
1 | 创建目录 |
执行完上面的命令后查看mycgroup目录发现多了几个文件:
1 | [root@node1 mycgroup]# ls |
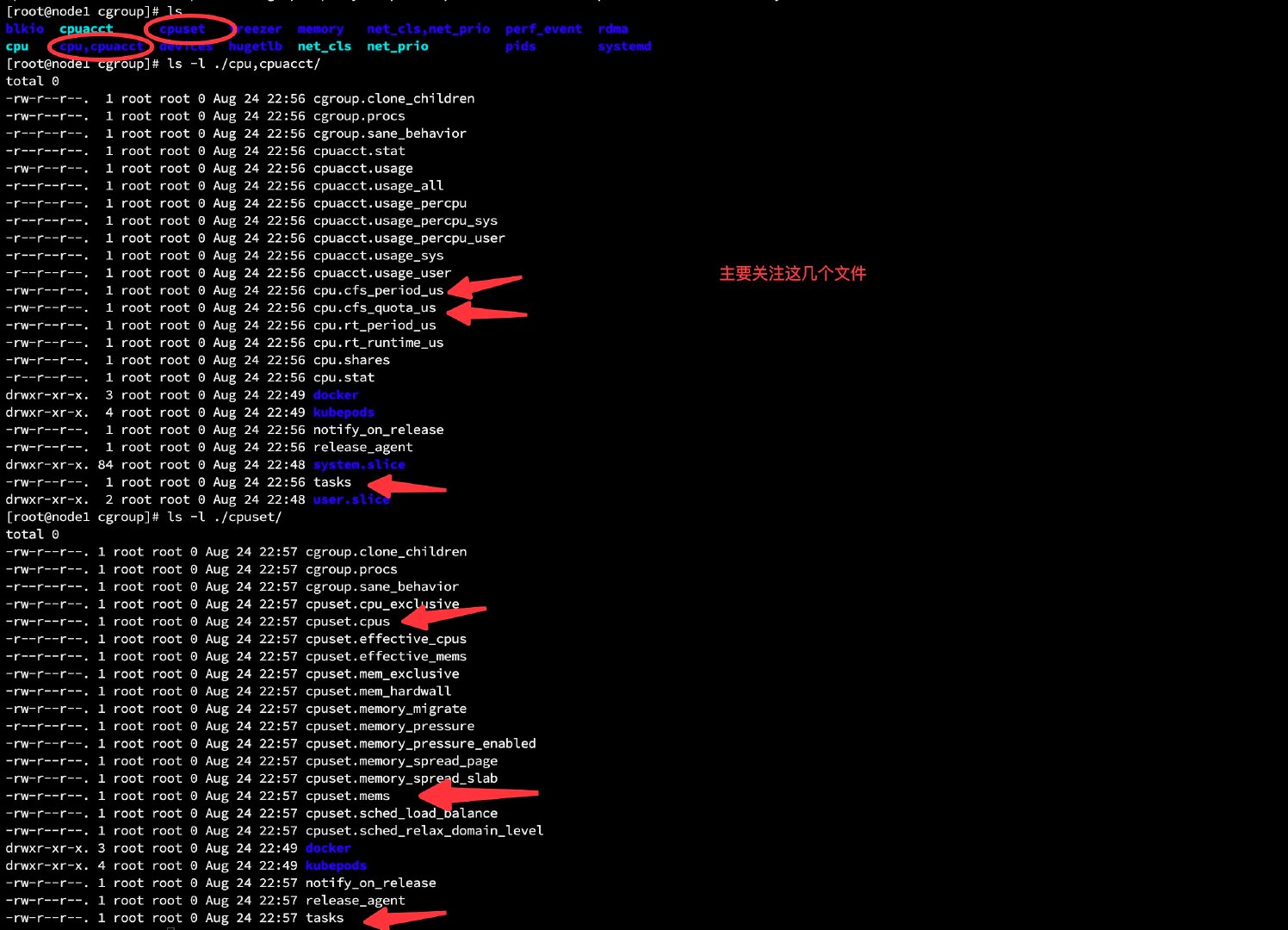
上面这些文件就是hierarchy中cgroup根节点的配置项,这些文件的含义是:
group.clone_childrencpuset的subsystem会读取这个配置文件,如果这个值(默认值是0)是 1 子cgroup才会继承父cgroup的cpuset的配置cgroup.procs是树中当前节点cgroup中的进程组ID,现在的位置是根节点,这个文件中会有现在系统中所有进程组的ID (查看目前全部进程PIDps -ef | awk '{print $2}')notify_on_release标志当这个cgroup最后一个进程退出的时候是否执行了release_agent(notify_on_release和release_agent会一起使用)release_agent则是一个路径,通常用作进程退出后自动清理不再使用的cgrouptask标识该cgroup下面进程ID,如果把一个进程ID写到task文件中,便会把相应的进程加入到这个cgroup中
在刚刚创建好的hierarchy上cgroup根节点中扩展出两个子cgroup, 它们会继承父cgroup的属性
通过subsystem限制cgroup中进程的资源
在上面创建的 hierarchy并没有关联到任何的subsystem, 需要我们手动创建subsystem挂载上去。
1 | mkdir -p mycgroup/memory && mount -t cgroup -o memory mycgroup-memory `pwd`/mycgroup/memory |
执行完上面命令后在memory会生成很多文件(这些文件其实是继承至/sys/fs/cgroup/memory), 其实不需要我们手动挂载cgroup,下面将演示如何使用cgroup进行资源限制~
如何使用cgroup进行资源限制
cgroups的创建很简单,只需要在相应的子系统下创建目录即可(默认是在/sys/fs/cgroup目录下), 接下来将演示如何限制cpu跟内存使用数量
1 | [root@node1 cgroup]# ls |
CPU 子系统
CPU子系统有两个目录, cpuset和cpu,cpuacct, 其中cpu,cpuacct用于设置cpu配额,cpuset用于设置cpu绑定(设置进程只能在指定的核上), 下面对cpu 子系统的一些字段进行说明:
cpu.cfs_period_us: 表示一个cpu带宽,单位为微秒(默认是10000000)。系统总CPU带宽: cpu核心数 * cfs_period_us。cpu.cfs_quota_us文件: 代表在某一个阶段限制的 CPU 时间总量,单位为微秒。cfs_quota_us为-1,表示使用的CPU不受cgroup限制。cfs_quota_us的最小值为1ms(1000),最大值为1s。 结合cfs_period_us可以限制进程使用的cpu。例如配置cfs_period_us=10000,而cfs_quota_us=20000。那么该进程就可以可以用2个cpu core。cpuacct.stat: 记录cgroup的所有任务(包括其子孙层级中的所有任务)使用的用户和系统CPU时间.cpuacct.usage: 记录这个cgroup中所有任务(包括其子孙层级中的所有任务)消耗的总CPU时间(纳秒)。cpuset.cpus: 指定允许这个 cgroup 中任务(进程)访问的 CPU。这是一个用逗号分开的列表,格式为 ASCII,使用小横线(”-“)代表范围。如下,代表 CPU 0、1、2 和 16。cpuset.mems: 指定允许这个 cgroup 中任务可访问的内存节点。这是一个用逗号分开的列表,格式为 ASCII,使用小横线(”-“)代表范围。如下代表内存节点 0、1、2 和 16。
- 创建CPU Cgroup
创建cpu子系统很简单,只需要在cpu子系统下创建一个目录即可。
1 | mkdir /sys/fs/cgroup/cpu/mydocker |
执行完上述命令后,我们查看一下我们新创建的目录下发生了什么?
1 | [root@node1 mydocker]# ls -l /sys/fs/cgroup/cpu/mydocker |
由上可以看到我们新建的目录下被自动创建了很多文件((这里利用到了继承,子进程会继承父进程的 cgroup))
- 创建进程,加入 cgroup
这里为了方便演示,我先把当前运行的 shell 进程加入 cgroup,然后在当前 shell 运行 cpu 耗时任务(这里利用到了继承,子进程会继承父进程的 cgroup)。
1 | cd /sys/fs/cgroup/cpu/mydocker |
- 设置cpu quote配额
1 | # 设置当前shell 可以使用1core cpu |
- 观察cgroup是否生效
1 | 当前shell |
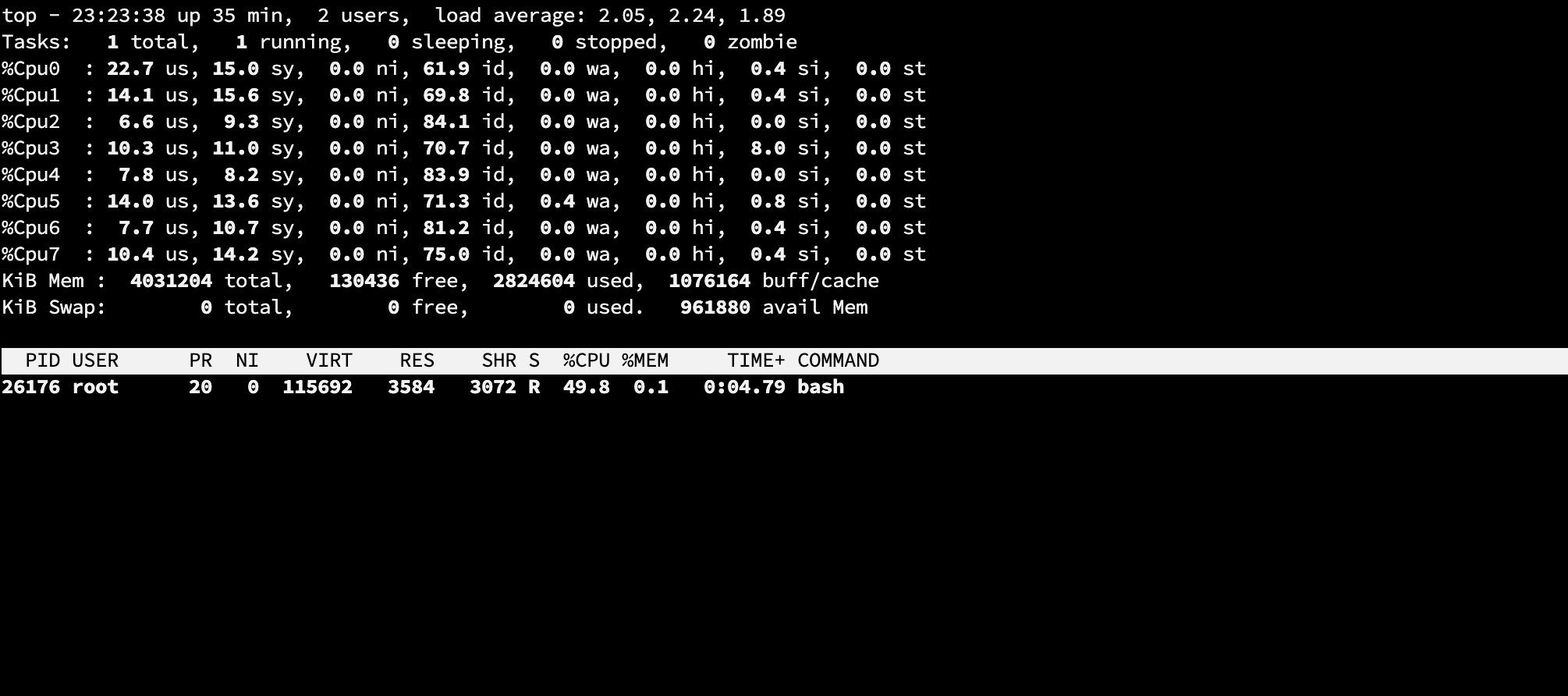
通过top命令可以看到刚才的shell 进程cpu已经达到了100%,说明cgroup起作用了.
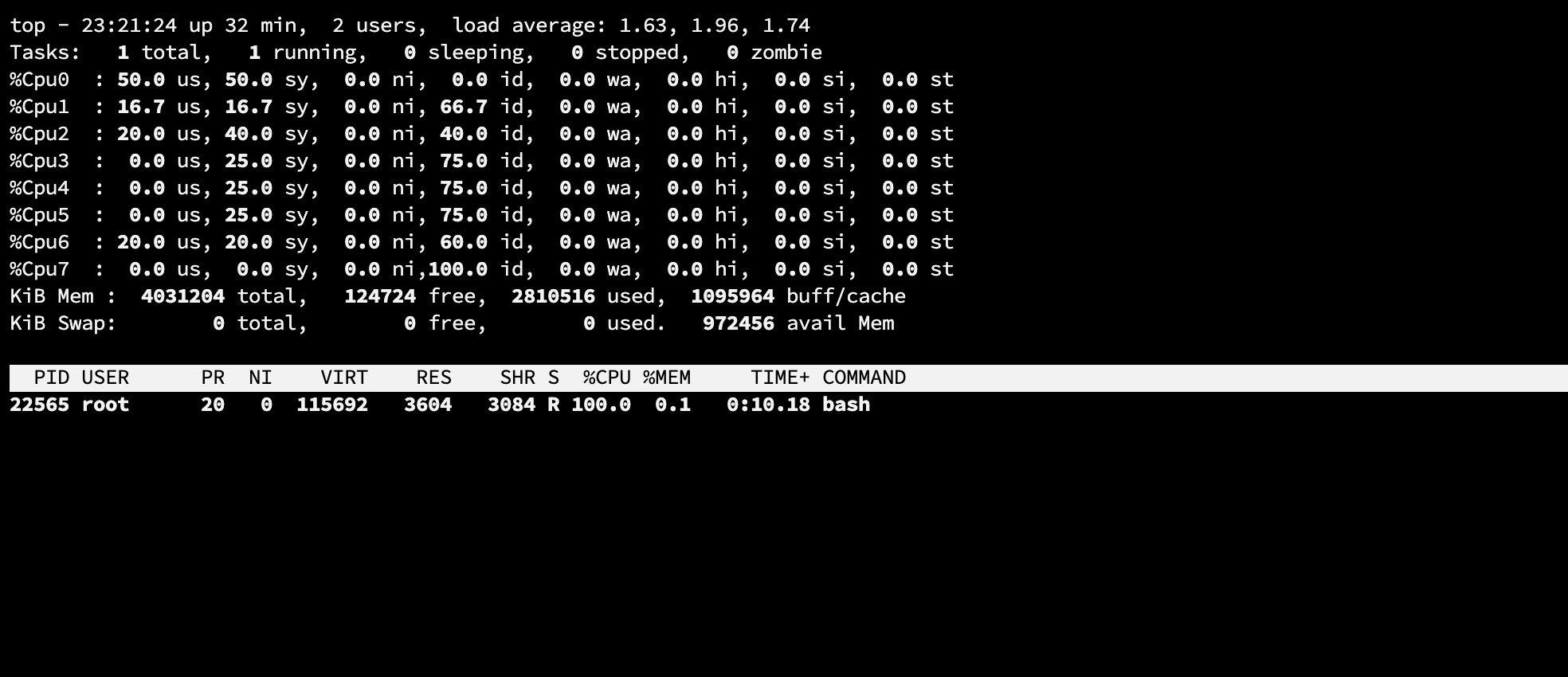
让我们更近一步,设置bash进程可以使用的cpu为0.5core, 通过echo 500000 > cpu.cfs_quota_us 然后继续观察,发现cpu到达50%后就上不去了。验证完 cgroup 限制 cpu,我们使用相似的方法来验证 cgroup 对内存的限制。
Memory 子系统
创建memory子系统的方式跟cpu子系统的方式差不多,只需要在memory子系统下创建一个目录即可。
- 在 memory 子系统下创建 cgroup
1 | mkdir /sys/fs/cgroup/memory/mydocker |
执行完上述命令后,我们查看一下我们新创建的目录下发生了什么?
1 | [root@node1 mydocker]# ls -l /sys/fs/cgroup/memory/mydocker |
由上可以看到我们新建的目录下被自动创建了很多文件(这里利用到了继承,子进程会继承父进程的 cgroup), 其中 memory.limit_in_bytes 文件代表内存使用总量,单位为 byte。例如,这里我希望对内存使用限制为 1G(1G = 102410241024),则向 memory.limit_in_bytes 文件写入 1073741824即可
- 创建进程,加入 cgroup
1 | cd /sys/fs/cgroup/memory/mydocker |
- 设置memory 配额
1 | # 设置当前shell 可以使用1G内存 |
- 观察cgroup是否生效
1 | # 使用stress-ng进行压力测试 |
通过运行stress-ng压力测试后,能发现终端会直接被卡死(其实无法说明Cgroup是否生效, 使用pidstat也不好查看内存占用情况)
pids子系统
参考文档
- 使用cgroups控制进程cpu配额 //图不错
- 一文彻底搞懂Linux Cgroup如何限制容器资源 //可以看看
- 资源限制:如何通过 Cgroups 机制实现资源限制? //推荐动手实验
- Cgroup中的CPU资源控制 //cgroup各个字段的含义