简述
在Go语言中,通过hash查找表实现map, 用链表发解决哈希冲突问题。通过key的哈希值将散落到不同的桶(bucket)中,每个桶有8个槽位(cell)。哈希值的低位决定key落入哪个桶,高位标识同一个桶中的不同 key。
map数据结构
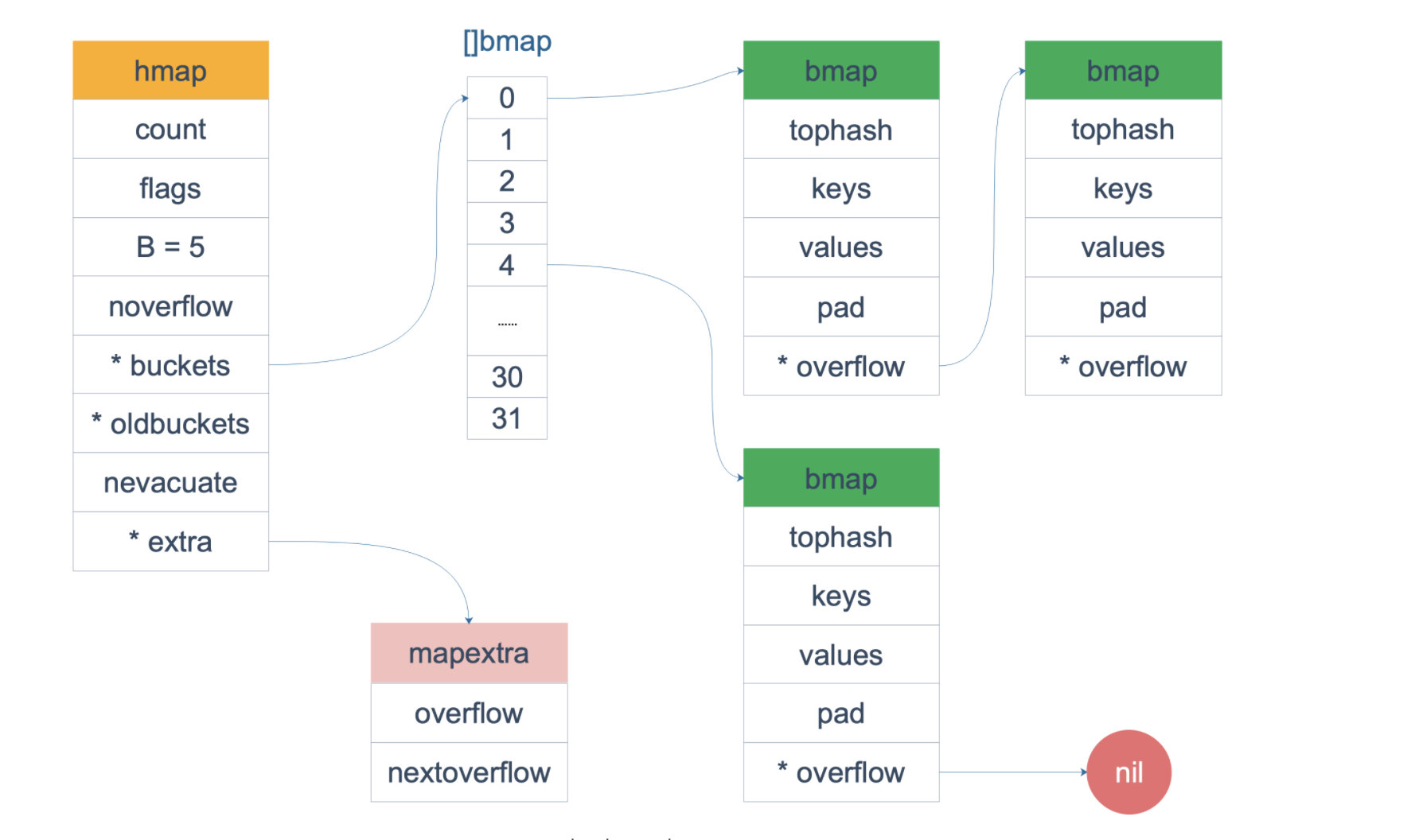
map的底层结构是hmap,他是hashmap的缩写
1 | // A header for a Go map. |
B 是 buckets 数组的长度的对数,也就是说 buckets 数组的长度就是 2^B, 相当于截断hash二进制后保留后面的B位。
buckets是一个指针(unsafe.Pointer —> 指针类型),最终指向的是一个结构体,在编译期间会增加几个字段,最终字段如下:
1 | type bmap struct { |
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
bmap是存放k-v的地方,key跟value放在一块,目的是节省内存空间,结构如下:

map整体数据结构如下:
map key定位
对map的添加更改主要涉及到key的定位过程,key经过哈希计算后得到哈希值,共 64 个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。如下图,首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。

map存值
首先用 key 的 hash 值低 8 位找到 bucket,然后在 bucket 内部比对 tophash 和高 8 位与其对应的 key 值与入参 key 是否相等,若找到则更新这个值。若 key 不存在,则 key 优先存入在查找的过程中遇到的空的 tophash 数组位置。若当前的 bucket 已满则需要另外分配空间给这个 key,新分配的 bucket 将挂在 overflow 链表后。
map扩容
触发 map 扩容的时机:在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容:
- 装载因子超过阈值,源码里定义的阈值是 6.5 (也就是每个buket都要装满了,总共8个)
- overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。(也就是某个bucket链太长了,而其他的bucket可能没有分配数据)
扩容分为等量扩容和 2 倍容量扩容。扩容后,原来一个 bucket 中的 key 一分为二,会被重新分配到两个桶中。扩容过程是渐进的,主要是防止一次扩容需要搬迁的 key 数量过多,引发性能问题。触发扩容的时机是增加了新元素,bucket 搬迁的时机则发生在赋值、删除期间,每次最多搬迁两个 bucket。

在遍历 map 时,并不是固定地从 0 号 bucket 开始遍历,每次都是从一个随机值序号的 bucket 开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。这样,即使是一个写死的 map,仅仅只是遍历它,也不太可能会返回一个固定序列的 key/value 对。
map删除
1 | // 对 key 清零 |
注意点
- map 并不是一个线程安全的数据结构。同时读写一个 map 是未定义的行为,如果被检测到,会直接 panic。
- ap删除操作仅仅将对应的 tophash[i]设置为 empty,并非释放内存。若要释放内存只能等待指针无引用后被系统 gc
- key必须是支持==或!=比较运算的类型,不可以是函数、map或slice(Go 语言中只要是可比较的类型都可以作为 key。除slice,map,functions 这几种类型,其他类型都是 OK 的。具体包括:布尔值、数字、字符串、指针、通道、接口类型、结构体、只包含上述类型的数组。)