网卡收包流程
Linux 网卡收包流程如下:
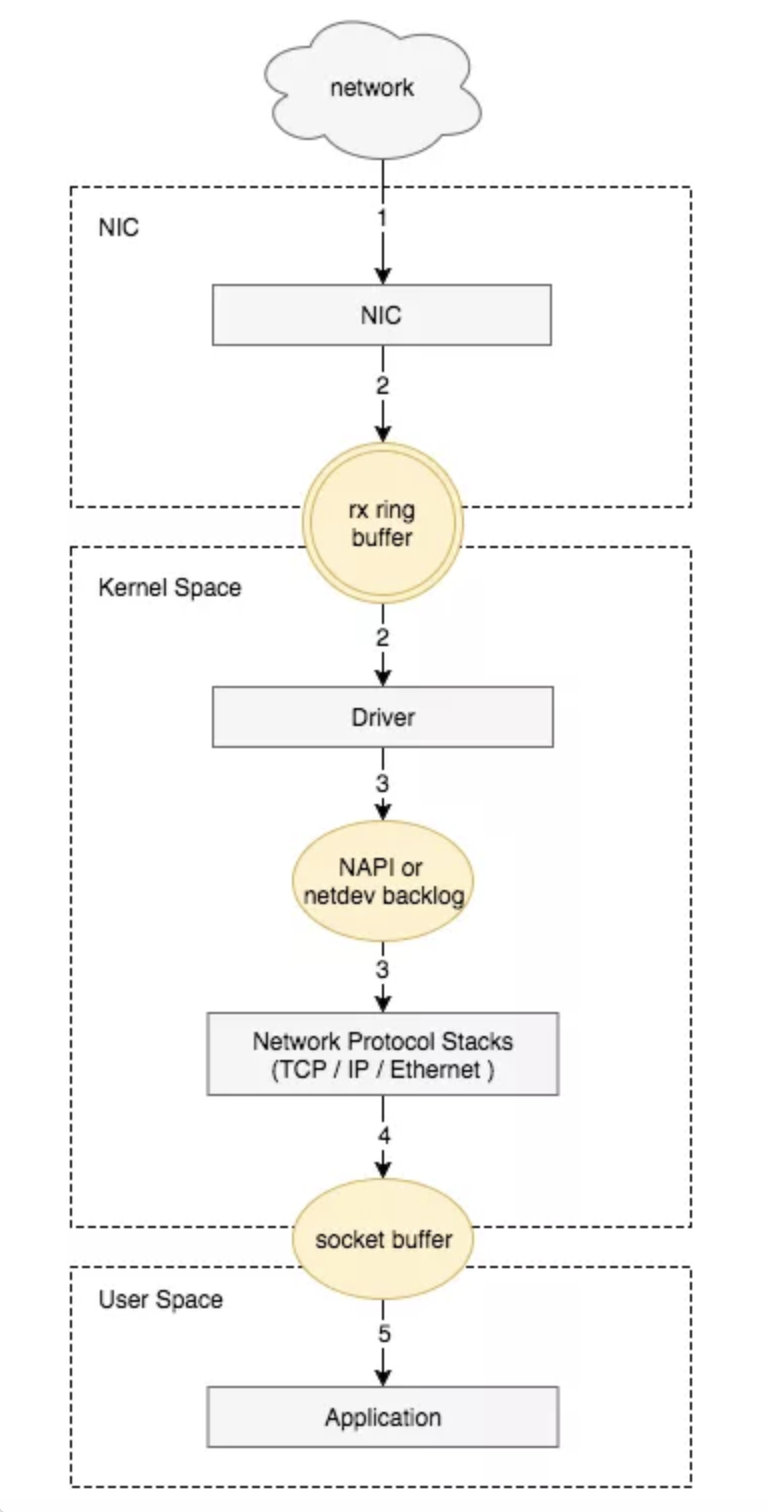
- 网卡收到数据包
- 将数据包从网卡硬件缓存移动到服务器内存中(DMA方式,不经过CPU)
- 通过硬中断通知CPU处理
- CPU通过软中断通知内核处理
- 经过TCP/IP协议栈处理
- 应用程序通过read()从socket buffer读取数据
网卡到内存中的问题排查
网卡丢包
我们先看下ifconfig的输出:
1 | # ifconfig eth0 |
RX(receive) 代表接收报文, TX(transmit) 表示发送报文。
- RX errors: 表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
- RX dropped: 表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
- RX overruns: 表示 fifo 的 overruns,由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,CPU 无法及时的处理中断是造成 Ring Buffer 满的原因之一,可能原因是因为 interruprs 分布的不均匀,没有做 affinity 而造成的丢包。
- RX frame: 表示 misaligned 的 frames。
dropped 与 overruns 的区别:
- dropped,表示这个数据包已经进入到网卡的接收缓存 fifo 队列,并且开始被系统中断处理准备进行数据包拷贝(从网卡缓存 fifo 队列拷贝到系统内存),但由于此时的系统原因(比如内存不够等)导致这个数据包被丢掉,即这个数据包被 Linux 系统丢掉。
- overruns,表示这个数据包还没有被进入到网卡的接收缓存 fifo 队列就被丢掉,因此此时网卡的 fifo 是满的。为什么 fifo 会是满的?因为系统繁忙,来不及响应网卡中断,导致网卡里的数据包没有及时的拷贝到系统内存, fifo 是满的就导致后面的数据包进不来,即这个数据包被网卡硬件丢掉。所以,如果遇到 overruns 非0,需要检测cpu负载与cpu中断情况。
环形队列Ring Buffer溢出
当网卡的缓存区(ring buffer)设置的太小。网络数据包到达(生产)的速率快于内核处理(消费)的速率时, Ring Buffer 很快会被填满,新来的数据包将被丢弃。
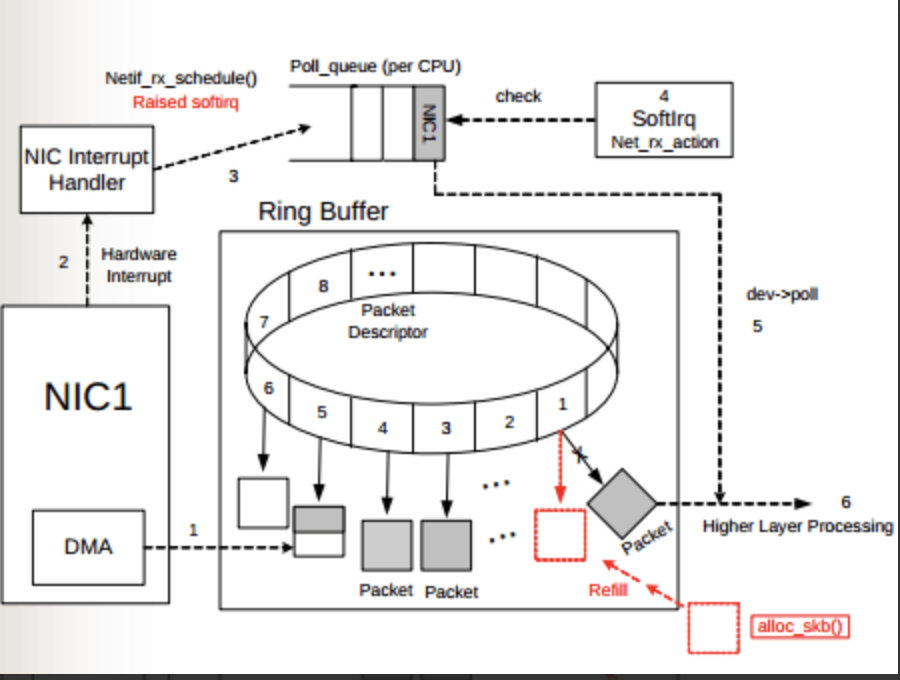
通过 ethtool 或 /proc/net/dev 可以查看因Ring Buffer满而丢弃的包统计
1 | [root@xxx ~]# ethtool -S ens2 | grep fifo |
可以通过ethtool 设置ring buffer 的缓冲区大小
1 | # 修改网卡eth0接收与发送硬件缓存区大小 |
中断过程中的问题
什么是中断
中断有两种:一种硬中断;一种软中断。硬中断是由硬件产生的,比如,像磁盘,网卡,键盘;软中断是由当前正在运行的进程所产生的。
硬中断,是一种由硬件产生的电信号直接发送到中断控制器上,然后由中断控制器向 CPU 发送信号,CPU 检测到该信号后,会中断当前的工作转而去处理中断。然后,处理器会通知内核已经产生中断,这样内核就会对这个中断进行适当的处理。
当网卡收到数据包时会产生中断请求(硬中断)通知到 CPU,CPU 会中断当前正在运行的任务,然后通知内核有新数据包,内核调用中断处理程序(软中断)进行响应,把数据包从网卡缓存及时拷贝到内存,否则会因为缓存溢出被丢弃。剩下的处理和操作数据包的工作就会交给软中断。
什么是多队列网卡
当网卡不断的接收数据包,就会产生很多中断,一个中断请求只能被一个CPU处理, 而现在的机器都是用多个CPU,同时只有一个 CPU 去处理 Ring Buffer 数据会很低效,这个时候就产生了叫做 Receive Side Scaling(RSS) 或者叫做 multiqueue 的机制来处理这个问题, 这就是为啥需要多队列的原因。
RSS(Receive Side Scaling)是网卡的硬件特性,实现了多队列。通过多队列网卡驱动加载,获取网卡型号,得到网卡的硬件 queue 的数量,并结合 CPU 核的数量,最终通过 Sum=Min(网卡 queue,CPU core)得出所要激活的网卡 queue 数量。
NIC 收到 Frame 的时候能通过 Hash Function 来决定 Frame 该放在哪个 Ring Buffer 上,触发的 IRQ 也可以通过操作系统或者手动配置 IRQ affinity 将 IRQ 分配到多个 CPU 上。这样 IRQ 能被不同的 CPU 处理,从而做到 Ring Buffer 上的数据也能被不同的 CPU 处理,从而提高数据的并行处理能力。
RSS 除了会影响到 NIC 将 IRQ 发到哪个 CPU 之外,不会影响别的逻辑。
什么是RPS
Receive Packet Steering(RPS) 是在 NIC 不支持 RSS 时候在软件中实现 RSS 类似功能的机制。其好处就是对 NIC 没有要求,任何 NIC 都能支持 RPS,但缺点是 NIC 收到数据后 DMA 将数据存入的还是一个 Ring Buffer,NIC 触发 IRQ 还是发到一个 CPU,还是由这一个 CPU 调用 driver 的 poll 来将 Ring Buffer 的数据取出来。RPS 是在单个 CPU 将数据从 Ring Buffer 取出来之后才开始起作用,它会为每个 Packet 计算 Hash 之后将 Packet 发到对应 CPU 的 backlog 中,并通过 Inter-processor Interrupt(IPI) 告知目标 CPU 来处理 backlog。后续 Packet 的处理流程就由这个目标 CPU 来完成。从而实现将负载分到多个 CPU 的目的。通常如果开启了RPS会加重所有 CPU 的负担.
IRQ 中断请求 亲和绑定
/proc/interrupts 文件中可以看到各个 CPU 上的中断情况。
/proc/irq/[irq_num]/smp_affinity_list 可以查看指定中断当前绑定的 CPU。
可以通过配置 IRQ affinity 指定 IRQ 由哪个 CPU 来处理中断, 先通过 /proc/interrupts 找到 IRQ 号之后,将希望绑定的 CPU 号写入 /proc/irq/IRQ_NUMBER/smp_affinity,写入的是 16 进制的 bit mask。比如看到队列 rx_0 对应的中断号是 41 那就执行:
1 | echo 6 > /proc/irq/41/smp_affinity |
0 号 CPU 的掩码是 0x1 (0001),1 号 CPU 掩码是 0x2 (0010),2 号 CPU 掩码是 0x4 (0100),3 号 CPU 掩码是 0x8 (1000) 依此类推。
softirq 数统计
通过 /proc/softirqs 能看到每个 CPU 上 softirq 数量统计:
1 | cat /proc/softirqs |
NET_RX 表示网卡收到包时候触发的 softirq,一般看这个统计是为了看看 softirq 在每个 CPU 上分布是否均匀,不均匀的话可能就需要做一些调整。比如上面看到 CPU0 和 CPU1 两个差距很大,原因是这个机器的 NIC 不支持 RSS,没有多个 Ring Buffer。开启 RPS 后就均匀多了。
如何开启RPS
RPS 默认是关闭的,当机器有多个 CPU 并且通过 softirqs 的统计 /proc/softirqs 发现 NET_RX 在 CPU 上分布不均匀或者发现网卡不支持 mutiqueue 时,就可以考虑开启 RPS。
开启 RPS 需要调整 /sys/class/net/DEVICE_NAME/queues/QUEUE/rps_cpus 的值。比如执行:
1 | echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus |
表示的含义是处理网卡 eth0 的 rx-0 队列的 CPU 数设置为 f 。即设置有 15 个 CPU 来处理 rx-0 这个队列的数据,如果你的 CPU 数没有这么多就会默认使用所有 CPU 。
netdev_max_backlog调优
netdev_max_backlog 是内核从 NIC 收到包后,交由协议栈(如 IP、TCP )处理之前的缓冲队列, 通过softnet_stat可以确定是否发生了netdev backlog队列溢出
1 | [root@xxx ~]# cat /proc/net/softnet_stat |
- 每一行代表每个 CPU 核的状态统计,从 CPU0 依次往下。
- 每一列代表一个 CPU 核的各项统计:第一列代表中断处理程序收到的包总数;第二列即代表由于 netdev_max_backlog 队列溢出而被丢弃的包总数。
- 第3列表示软中断一次取走netdev_budget个数据包,或取数据包时间超过2ms的次数。
- 第4~8列固定为0,没有意义。
- 第9列表示发送数据包时,对应的队列被锁住的次数。
netdev_max_backlog 的默认值是 1000,我们可以修改内核参数来调优:
1 | sysctl -w net.core.netdev_max_backlog=2000 |