概述
Elasticsearch是一个实时分布式存储、搜索、分析引擎;Elasticsearch的底层存储引擎是 Lucene,在这基础上提供分布式服务及RESTful API 实现高可用性。
ES具有如下的特点:
- 分布式:横向扩展非常灵活;
- 全文检索:基于lucene的强大的全文检索能力;
- 近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析;
- 高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据;
- 模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索;
基本概念
介绍ES的原理时,首先需要对ES中的一些术语有所了解,例如Document是啥,索引又是啥等等,下面就介绍ES的一些基本概念。
索引(Index)
索引是ES的逻辑存储,对应关系型数据库中的库,ES可以把索引数据存放到服务器中,也可以分片(Sharding)后存储到多台服务器上;每个索引可以有一个或多个分片,每个分片可以有多个副本
类型(Type)
在 ES 中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念;在ES 6.0开始,类型的概念被废弃,ES7中将它完全删除
文档(Document)
存储在ES中的主要实体被称为文档,可以理解为关系型数据库中表的一行数据记录,每个文档由多个字段(field)组成;文档的格式是json式的。对于文档,有几个主要的标识信息:_index(插入到哪个索引中),type(插入到哪个类型中),_id(文档的id是多少)
字段(Field)
Field是ES的最小单元,一个Document里面有多个Field, 每一个field都是一个数据字段,例如ID, Name
映射(Mapping)
mapping负责维护index中文档的结构,包括文档的字段名、字段数据类型、分词器、字段是否进行分词等,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,mapping中的字段类型根据字段的值来确定,如果数据是字符串,会生成text类型,并且默认进行分词。
字段类型根据数据格式自动识别的映射称之为动态映射(Dynamic Mapping),我们创建索引时自定义字段类型的映射称之为静态映射或显示映射(Explicit Mapping)。
节点(Node)
一个 ES 节点就是一个运行的 ES 实例,可以实现数据存储并且搜索的功能。每个节点都有一个唯一的名称作为身份标识,如果没有设置名称,默认使用 UUID 作为名称。最好给每个节点都定义上有意义的名称,在集群中区分出各个节点。大多数情况下每个 node 运行在一个独立的环境或虚拟机上(一个机器可以有多个实例,所以并不能说一台机器就是一个 node)。
ES上总有三种类型的节点:
- master node: 集群中的一个节点会被选为 master 节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集群或从集群中删除节点。master 节点无需参与文档层面的变更和搜索,这意味着仅有一个 master 节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为 master 节点。
- data node: 持有数据和倒排索引。默认情况下,每个节点都可以通过设定配置文件 elasticsearch.yml 中的 node.data 属性为 true (默认) 成为数据节点。如果需要一个专门的主节点 (一个节点既可以是 master 节点,同时也可以是 data 节点),应将其 node.data 属性设置为 false。
- coordinate node: 如果将 node.master 属性和 node.data 属性都设置为 false,那么该节点就是一个节点,扮演一个负载均衡的角色,将到来的请求路由到集群中的各个节点。
默认情况下,es集群节点都是混合节点,即在elasticsearch.yaml中默认
node.master:true和node.data:true
分片(shard)
单个节点由于物理机硬件限制,存储的文档是有限的,如果一个索引包含海量文档,则不能在单个节点存储。ES 提供分片机制,同一个索引可以存储在不同分片(数据容器)中。
分片有以下特点:
- 一个索引可以包含多个分片(shard);
- 每一个分片(shard)都是一个最小的工作单元,承载部分数据;
- 每个shard都是一个Lucene实例,有完整的简历索引和处理请求的能力;
- 增减节点时,shard会自动在nodes中负载均衡;
- 一个文档只能完整的存放在一个shard上;
- 一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的;
副本(replica)
副本(replica shard)就是shard的冗余备份,它的主要作用:
- 冗余备份,防止数据丢失;
- shard异常时负责容错和负载均衡;
对于一个索引,除非重建索引否则不能调整主分片的数目 (number_of_shards),但可以随时调整 replica 的数目 (number_of_replicas)。
集群(Cluster)
ES是一个分布式的数据分析引擎,因此可以由多个节点组成一个ES集群。
首先,每一个ElasticSearch服务端就是一个集群节点,当我们启动一个节点的时候,这个节点会自动创建一个集群,集群的名称默认为elasticsearch,当我们再次启动一个节点的时候,它首先会尝试寻找名称为elasticsearch的集群,然后加入其中,当节点加入到集群中后,这个集群就算是建立起来了(elasticsearch默认使用自动发现IP机制,即在当前网段内,只要能被自动感知到的IP就能自动加入到集群中)。
集群中主节点和其他节点之间通过 Ping 的方式互检查,主节点负责 Ping 所有其他节点,判断是否有节点已经挂掉。其他节点也通过 Ping 的方式判断主节点是否处于可用状态。
ES集群中,用户的请求默认发往协调节点(默认情况下,协调节点是集群中的任意节点,但是为了降低集群的负载,可以设置某些节点为集群节点,这样子所有的请求都会分发到这些节点上),并由该节点负责分发请求、收集结果等操作。
基本原理
ES数据写入流程
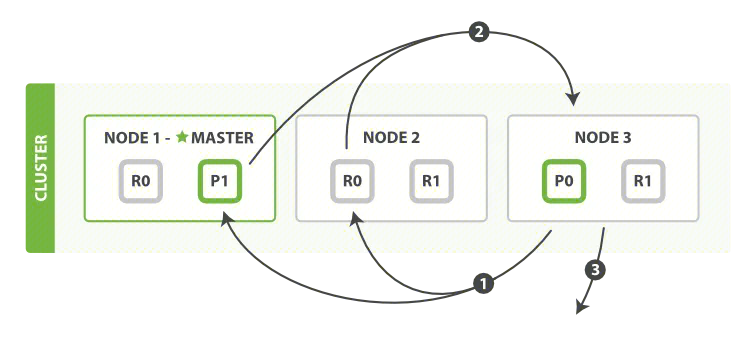
ES数据写入的时候是写到主分片(Primary Shard),当数据在 Primary 写入完成后会同步到响应的Replica Shard上,具体的过程如下:
- 客户端向Node1发送索引文档请求;
- Node1节点根据doc_id确定文档属于分片0,将请求转发到Node3
- Node3在主分片上执行请求,数据写入成功后将请求并行转发到副本分片所在节点Node2。一旦所有副本分片都写入成功(具体等待多少副本取决于
wait_for_active_shards的配置值),则Node3向协调节点返回写入成功,协调节点向客户端报告doc文档写入成功。
数据在协调节点向数据节点转发时,根据公式shard_num = hash(_routing) % num_primary_shards来计算文档具体是落入到哪个分片中,其中_routing的默认值是文档的ID。
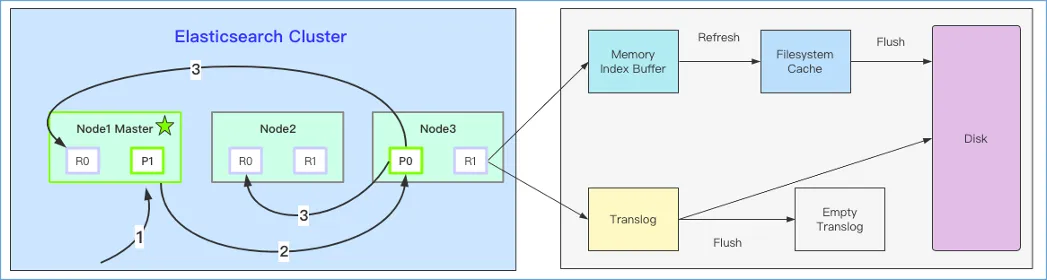
接下来我们深入看下文档在数据节点的写入过程,数据写入一般分为四个过程:
- Wirte过程:分片所在的节点在接收到协调节点的写入请求后,首先会将document写入到一个叫
In-Memory Buffer中,也被称为Indexing Buffer。这时候document还是不可搜索的状态,当In-Menory Buffer空间被写满后,会自动将In-Memory Buffer中的doc生成一个segment文件,这时候doc才会被搜索到; - Refresh过程:上面的write过程中,document会被首先写入到In-Memory Buffer中,In-Memory Buffer中的数据会在两种情况下被清空:第一种情况就是上面说的当In-Memory Buffer空间被写满了之后,ES会自动清空并生成一个Segment,第二种情况就是ES定时触发的Refresh操作,默认是1s执行一次。Refresh过程其实就是将In-Memory Buffer中的数据写入到Filesystem Cache中的过程,同时该过程也会生成一个Segment文件;
- Flush过程:上面的Write过程是将document写入到In-Memory Buffer中,而Refresh过程是将Doc刷新到文件系统缓存中。这两个过程的数据都还是在内存中,一旦机器故障或宕机重启,都有可能会出现数据丢失风险。ES为了数据丢失,通过translog机制来保障数据的可靠性,实现机制是接收到写入请求后同时将doc以key-value形式写入到translog文件中,当Filesystem Cache中数据被刷到磁盘中才会清空,其中Filesystem Cache中数据刷盘的过程就是Flush操作。从图2中也可以看出,执行了Flush操作后,In-Memory Buffer和translog中的数据都会被清空;
- Merge过程:ES的每一次Refresh操作,都会生成一个新的Segment段文件。这样会导致在短时间内段文件数量的暴涨。而段数目太多会带来一系列的问题,比如会大量消耗文件句柄,消耗内存和cpu运行周期。并且每个搜索请求都必须轮流检查每个段文件,导致搜索性能下降明显。为了解决这个问题,Elasticearch通过在后台维护一个线程来定期的合并这些Segment文件,将小的段合并到大的段,然后再将大的段合并到更大的段。这个合并的过程就是Segment Merge的过程。
段(segment):在ES中,单个倒排索引文件被称为Segment,每个分片底层又是一个个segment文件(段),每次数据的读写底层就是与一个个段文件的交互。segment中包含了原始数据和倒排索引等一系列数据和元数据信息。
总结下索引、shard与segment的关系为:ES的分片(shard )是Lucene的索引,ES的索引是分片的集合,Lucene的索引是由多个段(segment)组成

ES数据查询流程
ES的查询一般分为两个阶段,一个是查询阶段,一个是取数阶段
查询阶段
- 客户端发送一个
search请求到协调节点, 协调节点会创建一个大小为from + size的空优先队列。 - 协调节点将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为
from + size的本地有序优先队列中。 - 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表;
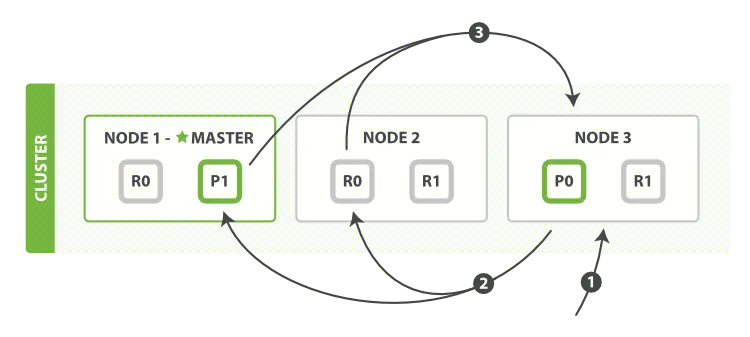
取数阶段
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
- 每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。