堆与栈的概念
即使是现代操作系统中,内存依然是计算机中很宝贵的资源,为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术,利用虚拟内存技术让每个进程都有4GB 互不干涉的虚拟地址空间。
进程初始化分配和操作的都是基于这个「虚拟地址」,只有当进程需要实际访问内存资源的时候才会建立虚拟地址和物理地址的映射,调入物理内存页。
4GB 的进程虚拟地址空间被分成两部分:「用户空间」和「内核空间」

不管是用户空间还是内核空间,使用的地址都是虚拟地址,当需进程要实际访问内存的时候,会由内核的「请求分页机制」产生「缺页异常」调入物理内存页
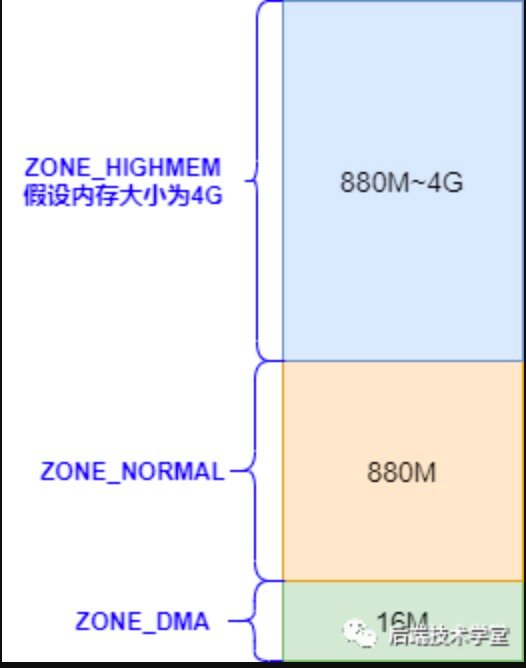
Linux 内核会将物理内存分为3个管理区分别是:
- DMA区域, 包含0MB~16MB之间的内存页框,直接映射到内核的地址空间(DMA好熟悉的感觉-^-)
- 普通内存区域, 包含16MB~896MB之间的内存页框,常规页框,直接映射到内核的地址空间。
- 高端内存区域。包含896MB以上的内存页框,不进行直接映射,可以通过永久映射和临时映射进行这部分内存页框的访问。
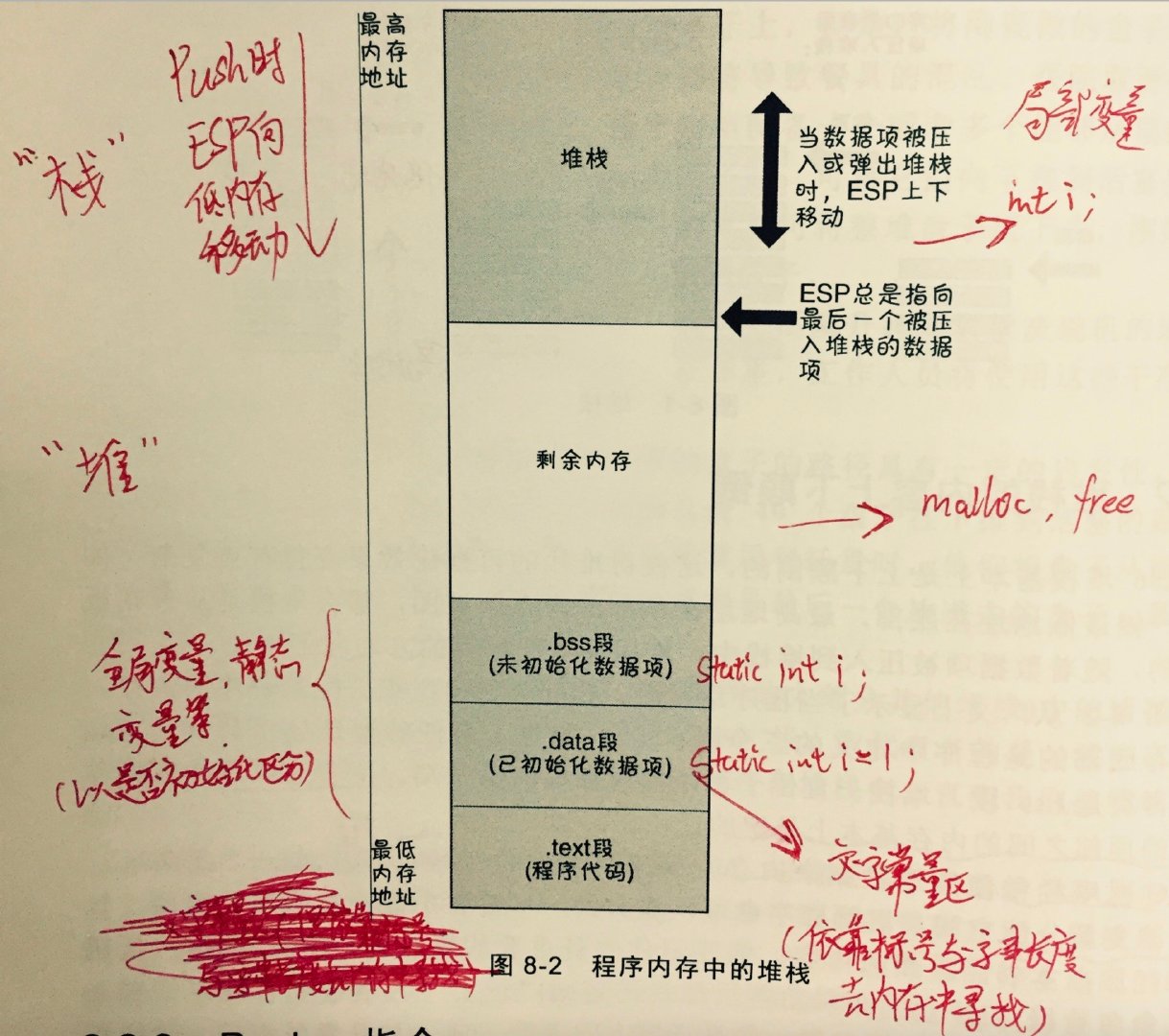
进程(执行的程序)占用的用户空间按照「 访问属性一致的地址空间存放在一起 」的原则,划分成 5个不同的内存区域,分别是 代码段, 数据段, BSS段, 堆 heap, 栈 stack
因此整个用户空间跟内核空间的映射关系如下:
堆与栈的区别
- 申请方式和回收方式不同
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
- 速度不同
栈:由系统自动分配,速度较快。但程序员是无法控制的。 堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片不过用起来最方便。
- 申请大小的限制
栈顶的地址和栈的最大容量是系统预先规定好的, 栈获得的空间较小。 堆的大小受限于计算机系统中有效的虚拟内存, 堆获得的空间比较灵活,也比较大。
go逃逸分析
在go中, 一个变量是在堆上分配,还是在栈上分配,是经过编译器的逃逸分析之后得出的结论。
在编译原理中,分析指针动态范围的方法称之为逃逸分析。通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸。
编译器会分析代码的特征和代码生命周期,Go中的变量只有在编译器可以证明在函数返回后不会再被引用的,才分配到栈上,其他情况下都是分配到堆上。
1 | 如果函数外部没有引用,则优先放到栈中; |
结语
堆上动态分配内存比栈上静态分配内存,开销大很多。
变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
Go编译器会在编译期对考察变量的作用域,并作一系列检查,如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。对于Go程序员来说,编译器的这些逃逸分析规则不需要掌握,我们只需通过go build-gcflags’-m’命令来观察变量逃逸情况就行了。
不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
最后,尽量写出少一些逃逸的代码,提升程序的运行效率。