Unix/Linux的体系架构
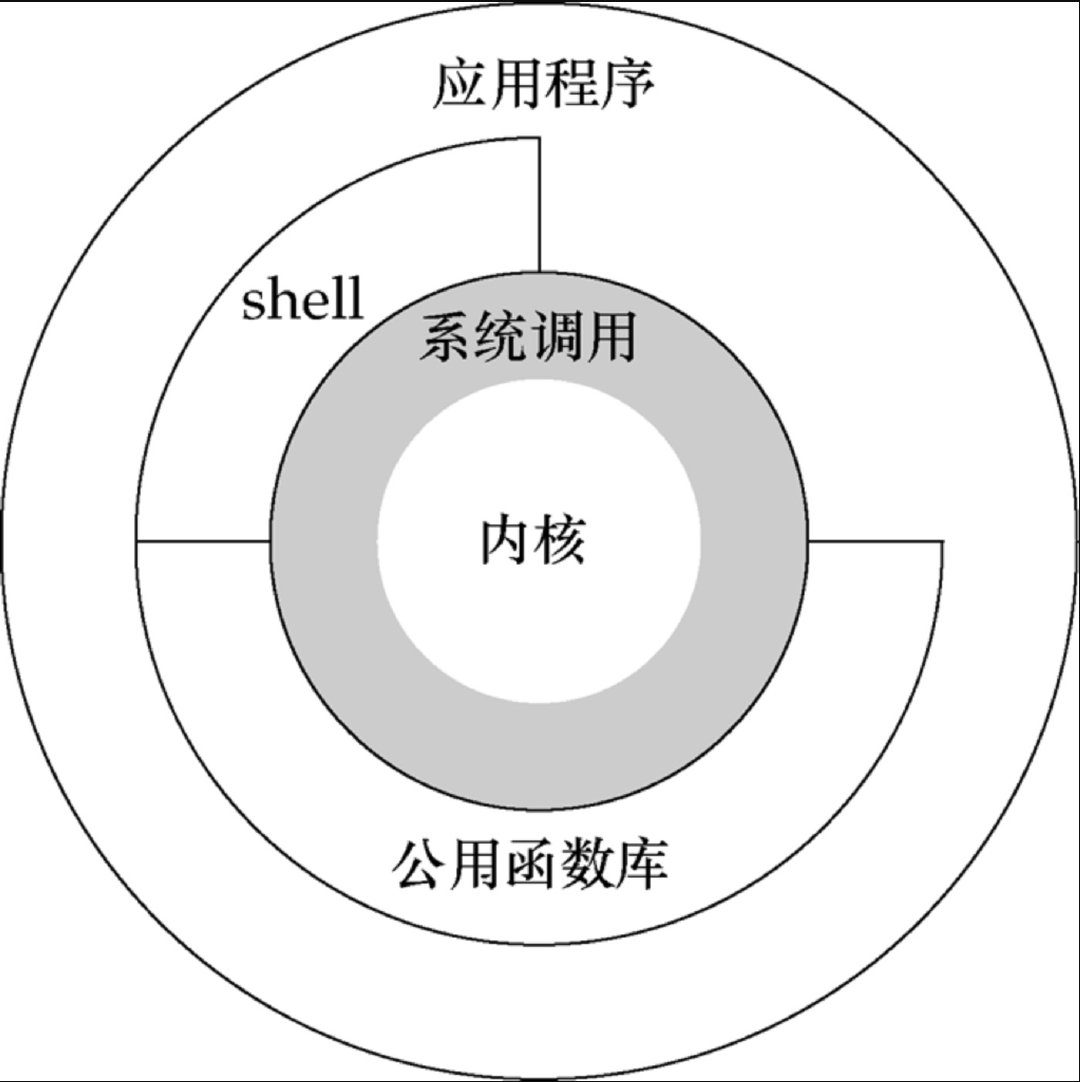
Linux操作系统的体系架构分为用户态和内核态(或者用户空间和内核)。内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用
系统调用是操作系统的最小功能单位,这些系统调用根据不同的应用场景可以进行扩展和裁剪,现在各种版本的Unix实现都提供了不同数量的系统调用,如Linux的不同版本提供了240-260个系统调用,FreeBSD大约提供了320个(reference:UNIX环境高级编程)
Shell是一个特殊的应用程序,俗称命令行,本质上是一个命令解释器,它下通系统调用,上通各种应用,通常充当着一种“胶水”的角色,来连接各个小功能程序,让不同程序能够以一个清晰的接口协同工作,从而增强各个程序的功能。同时,Shell是可编程的,它可以执行符合Shell语法的文本,这样的文本称为Shell脚本,通常短短的几行Shell脚本就可以实现一个非常大的功能,原因就是这些Shell语句通常都对系统调用做了一层封装。为了方便用户和系统交互,一般,一个Shell对应一个终端,终端是一个硬件设备,呈现给用户的是一个图形化窗口。我们可以通过这个窗口输入或者输出文本。这个文本直接传递给shell进行分析解释,然后执行。
运行级别
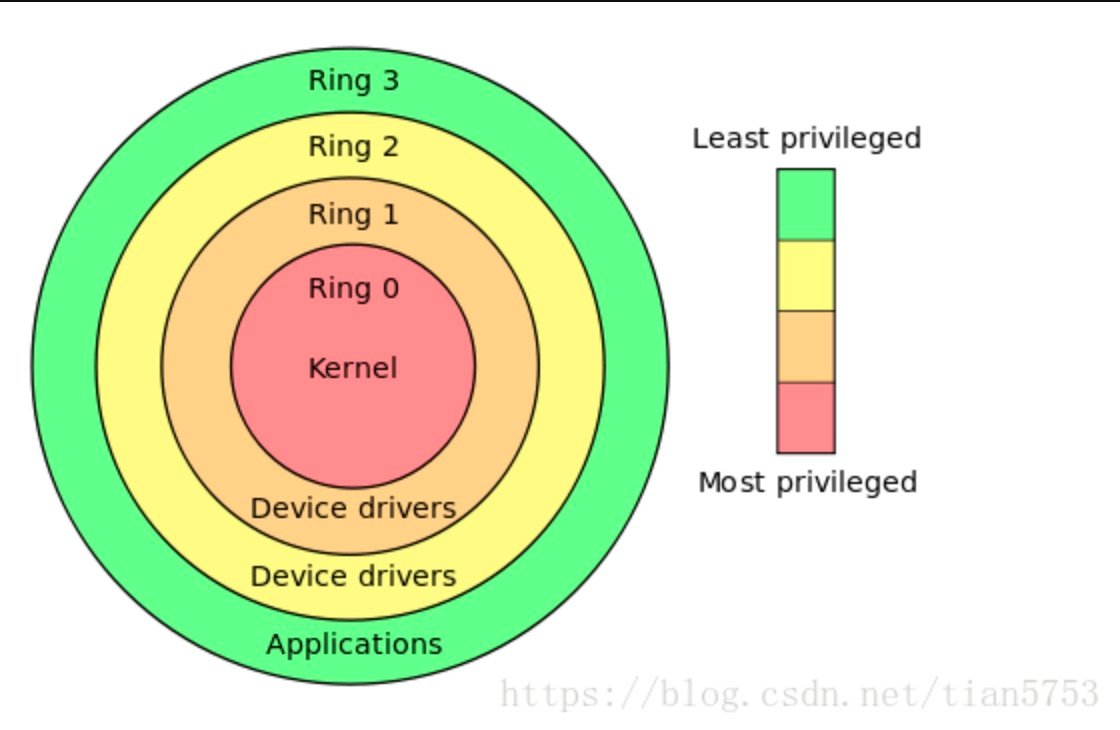
linux的运行级别如上所示, Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。Ring3状态不能访问Ring0的地址空间,包括代码和数据。
用户态通过系统调用切换成内核态,cpu通过跳转到系统调用对应的内核代码位置执行, 完成后再由内核态切回用户态
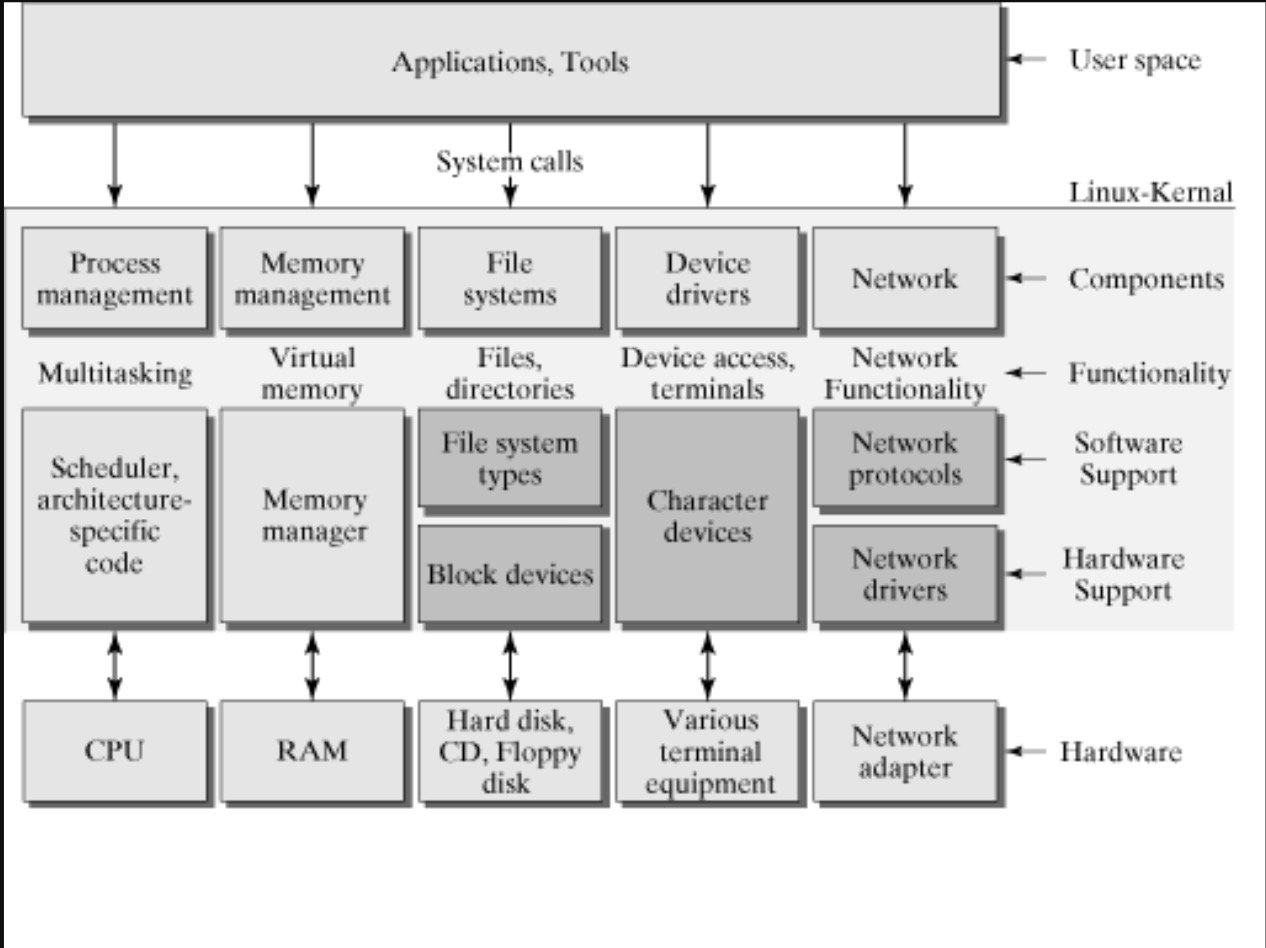
系统内核 向下控制硬件资源,向内管理操作系统资源:包括进程的调度和管理、内存的管理、文件系统的管理、设备驱动程序的管理以及网络资源的管理,向上则向应用程序提供系统调用的接口。
运行态切换
用户态的应用程序可以通过三种方式来访问内核态的资源
- 系统调用
- 异常事件
- 外围设备的中断
系统调用
因为操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。所以,为了减少有限资源的访问和使用冲突,Unix/Linux的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。Intel的X86架构的CPU提供了0到3四个特权级,数字越小,特权越高,Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。比如C函数库中的内存分配函数malloc(),它具体是使用sbrk()系统调用来分配内存,当malloc调用sbrk()的时候就涉及一次从用户态到内核态的切换,类似的函数还有printf(),调用的是wirte()系统调用来输出字符串,等等。
异常事件
当CPU正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常
外围设备中断
当外围设备完成用户的请求操作后,会像CPU发出中断信号,此时,CPU就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换。
系统调用的本质其实也是中断,相对于外围设备的硬中断,这种中断称为软中断,这是操作系统为用户特别开放的一种中断,如Linux int 80h中断。所以,从触发方式和效果上来看,这三种切换方式是完全一样的,都相当于是执行了一个中断响应的过程。但是从触发的对象来看,系统调用是进程主动请求切换的,而异常和硬中断则是被动的。
常用系统调用方式
procfs(/proc)
procfs 是 进程文件系统 的缩写,它本质上是一个伪文件系统,为什么说是 伪 文件系统呢?因为它不占用外部存储空间,只是占用少量的内存,通常是挂载在 /proc 目录下。
我们在该目录下看到的一个文件,实际上是一个内核变量。内核就是通过这个目录,以文件的形式展现自己的内部信息,相当于 /proc 目录为用户态和内核态之间的交互搭建了一个桥梁,用户态读写 /proc 下的文件,就是读写内核相关的配置参数。
比如常见的 /proc/cpuinfo、/proc/meminfo 和 /proc/net 就分别提供了 CPU、内存、网络的相关参数。除此之外,还有很多的参数
1 | root@ubuntu:~# ls /proc/ |
可以看到,这里面有很多的数字表示的文件,这些其实是当前系统运行的进程文件,数字表示进程号(PID),每个文件包含该进程所有的配置信息,包括进程状态、文件描述符、内存映射等等,我们可以看下:
1 | root@ubuntu:~# ls /proc/1/ |
综上,内核通过一个个的文件来暴露自己的系统配置信息,这些文件,有些是只读的,有些是可写的,有些是动态变化的,比如进程文件,当应用程序读取某个 /proc/ 文件时,内核才会去注册这个文件,然后再调用一组内核函数来处理,将相应的内核参数拷贝到用户态空间,这样用户读这个文件就可以获取到内核的信息。一个大概的图示如下所示:
procfs
sysctl(/proc/sys)
我们熟悉的 sysctl 是一个 Linux 命令,man sysctl 可以看到它的功能和用法。它主要是被用来修改内核的运行时参数,换句话说,它可以在内核运行过程中,动态修改内核参数。
它本质上还是用到了文件的读写操作,来完成用户态和内核态的通信。它使用的是 /proc 的一个子目录 /proc/sys。和 procfs 的区别在于:
procfs 主要是输出只读数据,而 sysctl 输出的大部分信息是可写的。
例如,我们比较常见的是通过 cat /proc/sys/net/ipv4/ip_forward 来获取内核网络层是否允许转发 IP 数据包,通过 echo 1 > /proc/sys/net/ipv4/ip_forward 或者 sysctl -w net.ipv4.ip_forward=1 来设置内核网络层允许转发 IP 数据包。
同样的操作,Linux 也提供了文件 /etc/sysctl.conf 来让你进行批量修改。
sysfs(/sys)
sysfs 是 Linux 2.6 才引入的一种虚拟文件系统,它的做法也是通过文件 /sys 来完成用户态和内核的通信。和 procfs 不同的是,sysfs 是将一些原本在 procfs 中的,关于设备和驱动的部分,独立出来,以 “设备树” 的形式呈现给用户。
sysfs 不仅可以从内核空间读取设备和驱动程序的信息,也可以对设备和驱动进行配置。
我们看下 /sys 下有什么:
1 | # ls /sys |
netlink 套接口
netlink 是 Linux 用户态与内核态通信最常用的一种方式。Linux kernel 2.6.14 版本才开始支持。它本质上是一种 socket,常规 socket 使用的标准 API,在它身上同样适用。
netlink 这种灵活的方式,使得它可以用于内核与多种用户进程之间的消息传递系统,比如路由子系统,防火墙(Netfilter),ipsec 安全策略等等。
用户空间和内核空间
用户空间就是用户进程所在的内存区域,系统空间就是操作系统占据的内存区域。用户进程和系统进程的所有数据都在内存中。
在电脑开机之前,内存就是一块原始的物理内存。什么也没有。开机加电,系统启动后,就对物理内存进行了划分。当然,这是系统的规定,物理内存条上并没有划分好的地址和空间范围。这些划分都是操作系统在逻辑上的划分。不同版本的操作系统划分的结果都是不一样的。例如在32位操作系统中,一般将最高的1G字节划分为内核空间,供内核使用,而将较低的3G字节划分为用户空间,供各个进程使用。
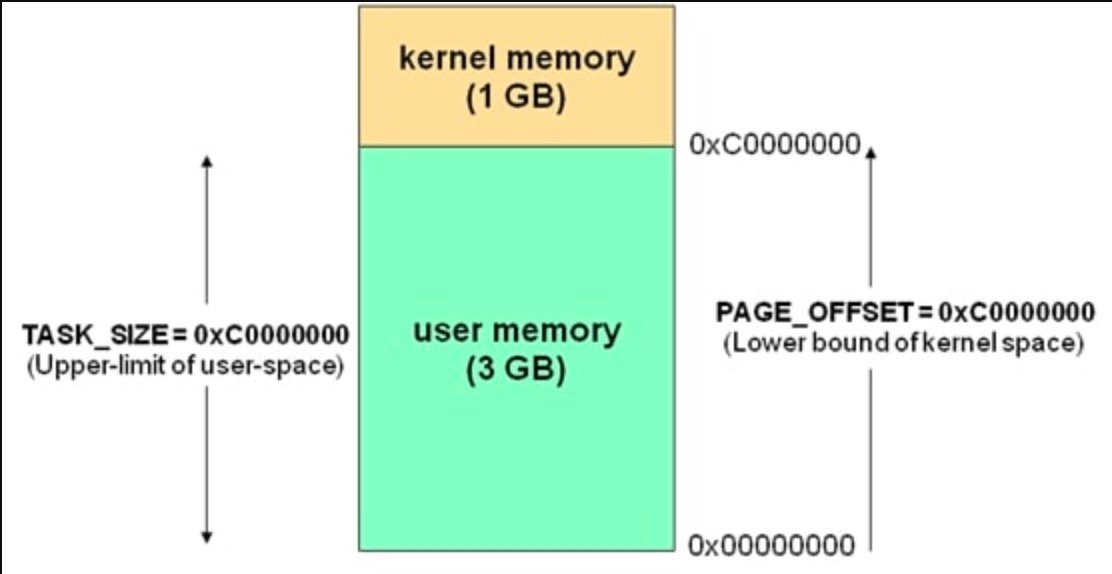
其中:
- 内核空间中存放的是内核代码和数据,而进程的用户空间中存放的是用户程序的代码和数据。
- 进程在运行的时候,在内核空间和用户空间各有一个堆栈。
- 用户空间中,每个进程的用户空间是互相独立的,互不相干。
- 内核空间中,绝大部分是共享的,并不是完全共享,因为内核空间中,不同进程的内核栈之间是不共享的。
参考文档
- https://cllc.fun/2019/03/02/linux-user-kernel-space //用户空间与内核空间简述
- Linux探秘之用户态与内核态 //Linux云计算网络
- 转 cpu 寄存器 内核态 用户态