kubernetes的运行流程
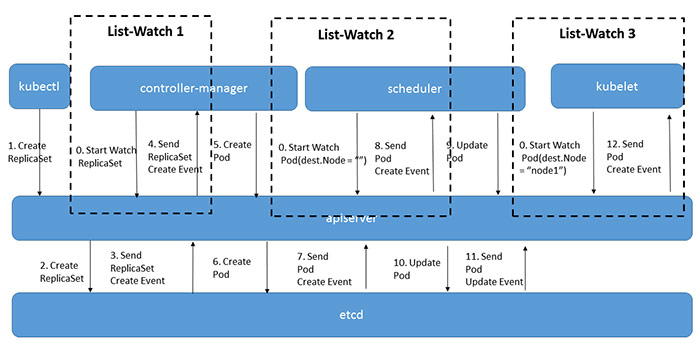
当kubectl创建了ReplicaSet对象后,controller-manager都是通过list-watch这种方式得到了最新的ReplicaSet对象,并执行自己的逻辑来创建Pod对象
其他的几个组件,Scheduler/Kubelet也是一样,通过list-watch得知变化并进行处理。
list-watch机制
kubernetes系统的采取Level Trigger而非Edge Trigger的设计理念,所以各组件只需要感知数据最新的状态,而不需要担心错过数据的变化过程。
list-watach机制需要满足以下需求:
- 实时性(即数据变化时,相关组件越快感知越好)
- 保证消息的顺序性(即消息要按发生先后顺序送达目的组件。很难想象在Pod创建消息前收到该Pod删除消息时组件应该怎么处理)
- 保证消息不丢失或者有可靠的重新获取机制(比如说kubelet和kube-apiserver间网络闪断,需要保证网络恢复后kubelet可以收到网络闪断期间产生的消息)
list-watch由list和watch组成,list调用资源的list API罗列资源,基于HTTP短链接实现。 watch调用资源的watch API监听资源变更事件,基于HTTP 长链接实现。
当客户端调用 watch API 时,apiserver 在 response 的 HTTP Header 中设置 Transfer-Encoding 的值为 chunked,表示采用分块传输编码,客户端收到该信息后,便和服务端该链接,并等待下一个数据块,即资源的事件信息。
为了满足1,2要求, kubernetes中为每一个REST数据加了一个ResourceVersion字段,并且该字段的值由ETCD来保证全局单调递增(当ETCD中写入一个数据时,全局ResourceVersion就加1)。这样就保证了不同时刻的数据ResourceVersion不同,并且后产生数据的ResourceVersion较之前数据的ResourceVersion大。这样客户端发起watch请求时,只需要带上请求数据在本地缓存中的最新ResourceVersion,而服务端就根据ResourceVersion从小到大把 大于客户端ResourceVersion的数据按顺序推送给客户端即可。这样就保证了推送数据的顺序性。

为了满足3要求, watch请求开始之前,先发起一次list请求,获取集群中当前所有该类数据(同时得到最新的ResourceVersion),之后基于最新的ResourceVersion发起watch请求, 当watch出错时(比如说网络闪断造成客户端和服务端数据不同步),重新发起一次list请求获取所有数据,再重新基于最新ResourceVersion来watch.
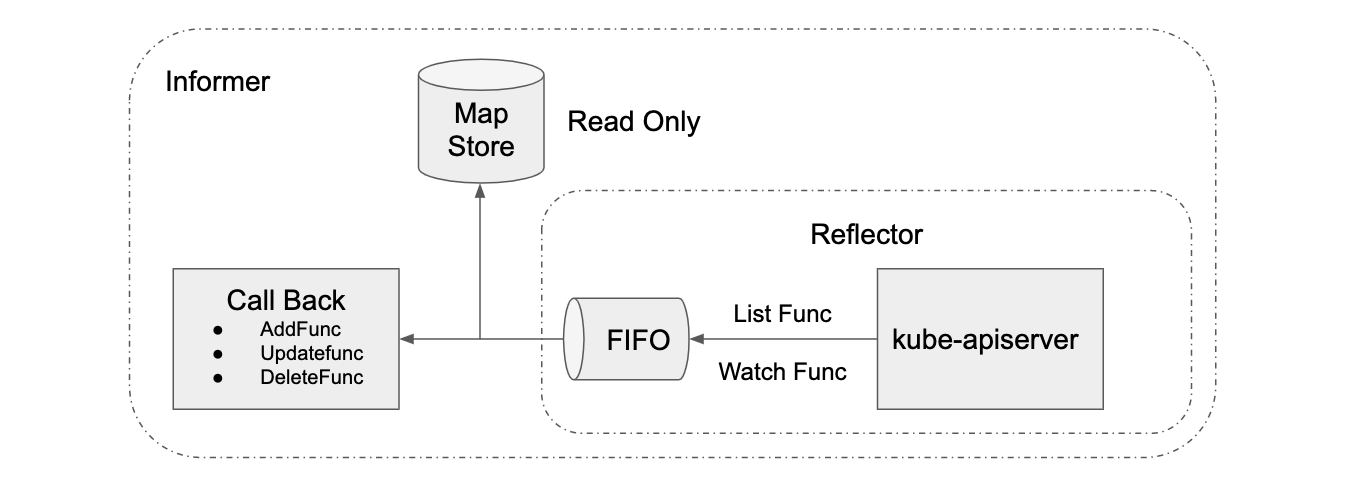
informer机制
K8S 的 informer 模块封装 list-watch API,用户只需要指定资源,编写事件处理函数,AddFunc, UpdateFunc 和 DeleteFunc 等。如下图所示,informer 首先通过 list API 罗列资源,然后调用 watch API 监听资源的变更事件,并将结果放入到一个 FIFO 队列,队列的另一头有协程从中取出事件,并调用对应的注册函数处理事件。Informer 还维护了一个只读的 Map Store 缓存,主要为了提升查询的效率,降低 apiserver 的负载。
参考文档
- https://zhuanlan.zhihu.com/p/59660536 //理解 K8S 的设计精髓之 List-Watch机制和Informer模块
- https://juejin.im/entry/5ad95f55f265da0b767d042d //kubernetes的设计理念
- https://yq.aliyun.com/articles/679797 //Kubernetes(k8s)代码解读-apiserver之list-watch篇